PEFT (Parameter Efficient Fine Tuning) – This term can make anyone curious, and today we will discuss everything about PEFT in this blog.
In the ever-evolving sphere of Natural Language Processing (NLP), a seismic shift has occurred. With the introduction of Large Language Models (LLMs) such as GPT, T5, and BERT, all grounded in the innovative transformer architecture. This shift isn’t contained solely within NLP but spreading its tendrils into other disciplines like Computer Vision (CV) and the auditory field. Technologies like VIT, Stable Diffusion, LayoutLM, Whisper, and XLS-R are pioneers of this multi-disciplinary expansion.
These models, upon inception, are pretrained on extensive, non-specific datasets, forming a versatile base. This base is later honed and optimized for specific target functions or downstream tasks, a method known as fine-tuning.
Fine-tuning isn’t merely a standard procedure; it’s an art that leads to remarkable improvements in performance. When pretrained LLMs are adapted and customized for downstream applications, they can surpass the efficacy of utilizing them directly without modifications (a zero-shot inference approach). But a shadow falls over this bright landscape as models expand in complexity and size: full fine-tuning begins to strain the capabilities of ordinary consumer-grade hardware.
Furthermore, the individual storage and deployment of separately fine-tuned models for distinct downstream tasks present a new challenge. The financial burden becomes considerable since the fine-tuned models maintain the same dimensions as their original, pretrained counterparts.
At this junction, the methodology known as Parameter-Efficient Fine-tuning, or PEFT, emerges as a beacon. PEFT, also called “parameter-efficient transfer learning for NLP,” offers elegant and strategic answers to these pressing issues, symbolizing a new horizon in the ongoing quest for greater efficiency and performance in artificial intelligence. Its presence testifies to these models’ incredible adaptability and potential.
What is Parameter Efficient Fine Tuning (PEFT)?
Innovation is crucial in the constantly expanding field of Natural Language Processing (NLP). Therefore, think of PEFT, or parameter-efficient transfer learning for NLP, as the rocket fuel for the pre-trained language models. It includes directing already-existing talent in a new path while using it and improving performance without starting from scratch.
PEFT’s charm comes from its sophisticated computational architecture. Moreover, the pre-trained model may adapt to new challenges with minimal computational strain by locking particular layers and concentrating on the tail end. This is similar to the engineering marvel of reusable rocket technology, using what has been done to reach greater heights.
This concept is not entirely new. Instead, it is a copy of the computer vision technology known as transfer learning. Early word embedding research laid the foundation for more current technological advancements.
To power language models like BERT and RoBERTa, PEFT’s efficacy is being employed. This impacts many downstream processes, such as sentiment analysis, entity recognition, and difficult question answering. Judiciously allocating resources and changing a small subset of the model parameters decreases the danger of overfitting.
Finally, PEFT shows the power of intelligent engineering and the enormous potential of what is presently available. It is a thoughtful use of resources consistent with advancement’s very nature.
The Parameter Efficient Fine Tuning (PEFT) Paradigm
Initiating with Pre-Configuration – Subsequent Customization Scheme.
The phase of LLM Pre-configuration predominantly encompasses the employment of significantly over-specified transformers. Such transformers function as the fundamental framework, shaping the natural language through various methodologies. These include bidirectional, autoregressive, and sequence-to-sequence approaches applied to expansive, unsupervised text collections. Once this primary stage is completed, downstream tasks follow where bespoke objectives are integrated to meticulously adjust the pre-configured LLM, allowing it to adapt to specialized models.
A salient trend is an inescapable escalation in the scale of pre-configured LLMs, as gauged by their parameter count. This upward trajectory seems unavoidable, given that consistent empirical findings validate that the enlargement of models, in conjunction with a corresponding increase in data, almost invariably amplifies their efficacy. To illustrate this point, the Generative Pre-trained Transformer (GPT-3), with a staggering count of 175 billion parameters, can craft the natural language of an unparalleled caliber, executing a diverse spectrum of zero-shot functions with acceptable outcomes when provided with suitable instructions.
Following this development, expansive models such as Gopher, Megatron-Turing Natural Language Generation (NLG), and Pathways Language Model (PaLM) have consistently demonstrated their applicability across various downstream applications. Although in-context learning has presented itself as a fruitful avenue, especially for pre-configured LLMs like GPT-3, task-specific fine-tuning has an edge.
However, there is an increasing challenge in dealing with large-scale models through the conventional approach of full parameter fine-tuning. This method, starting with pre-configured weights and then updating the entire set of parameters to create unique instances for diverse functions, becomes increasingly impractical with extensive models. Embracing techniques like PEFT (parameter-efficient transfer learning for NLP) can help mitigate these challenges. However, beyond the computational and deployment expenditure, storing distinct instances for varied tasks becomes exceptionally demanding on memory resources.
What Distinguishes Standard Fine-Tuning From Its Parameter Efficient Fine Tuning Counterpart in Machine Learning?
In machine learning, fine-tuning and parameter-efficient fine-tuning play pivotal roles. Specifically, they enhance the functionality of pre-existing models for specialized tasks.
Fine-tuning involves taking a previously trained model and advancing its training for a specific, novel task with fresh data. The entire architecture of the model, encompassing every layer and parameter, is subject to this further training. Though a robust approach, this method can become a resource-intensive and time-consuming endeavor, particularly when dealing with sophisticated, large-scale models.
Conversely, parameter-efficient transfer learning for NLP adopts a more streamlined process. It’s an innovation in fine-tuning where the focus is on training only a selective part of the pre-trained model’s parameters. Consequently, by isolating and concentrating on the parameters most relevant to the new task, PEFT optimizes the training procedure. The essence of this approach lies in the discernment of vital parameters and updating only those during the training phase. As a result, PEFT dramatically minimizes the computational demands, making it a more efficient route for model refinement.
|
Criteria |
Parameter-efficient Fine Tuning (PEFT) |
Conventional Fine-tuning |
|
Objective |
Enhance pre-trained models in data-scarce, low-compute areas |
Boost pre-trained models with ample data & compute |
|
Data Necessity |
Limited examples in the dataset |
Abundant examples in the dataset |
|
Time Required for Training |
Quicker relative to the conventional method |
Slower relative to PEFT |
|
Resource Consumption |
Economizes computational means |
Utilizes extensive computational means |
|
Model Parameter Adjustment |
Alters select model components |
Overhauls entire model structure |
|
Overfitting Susceptibility |
Lower risk due to restricted modification |
Higher risk due to thorough modification |
|
Outcome of Training |
Adequate but generally below conventional method |
Usually outperforms PEFT |
|
Typical Applications |
Best in resource-constrained or data-limited situations |
Optimal for resource-rich environments |
Benefits of Parameter Efficient Fine Tuning (PEFT)
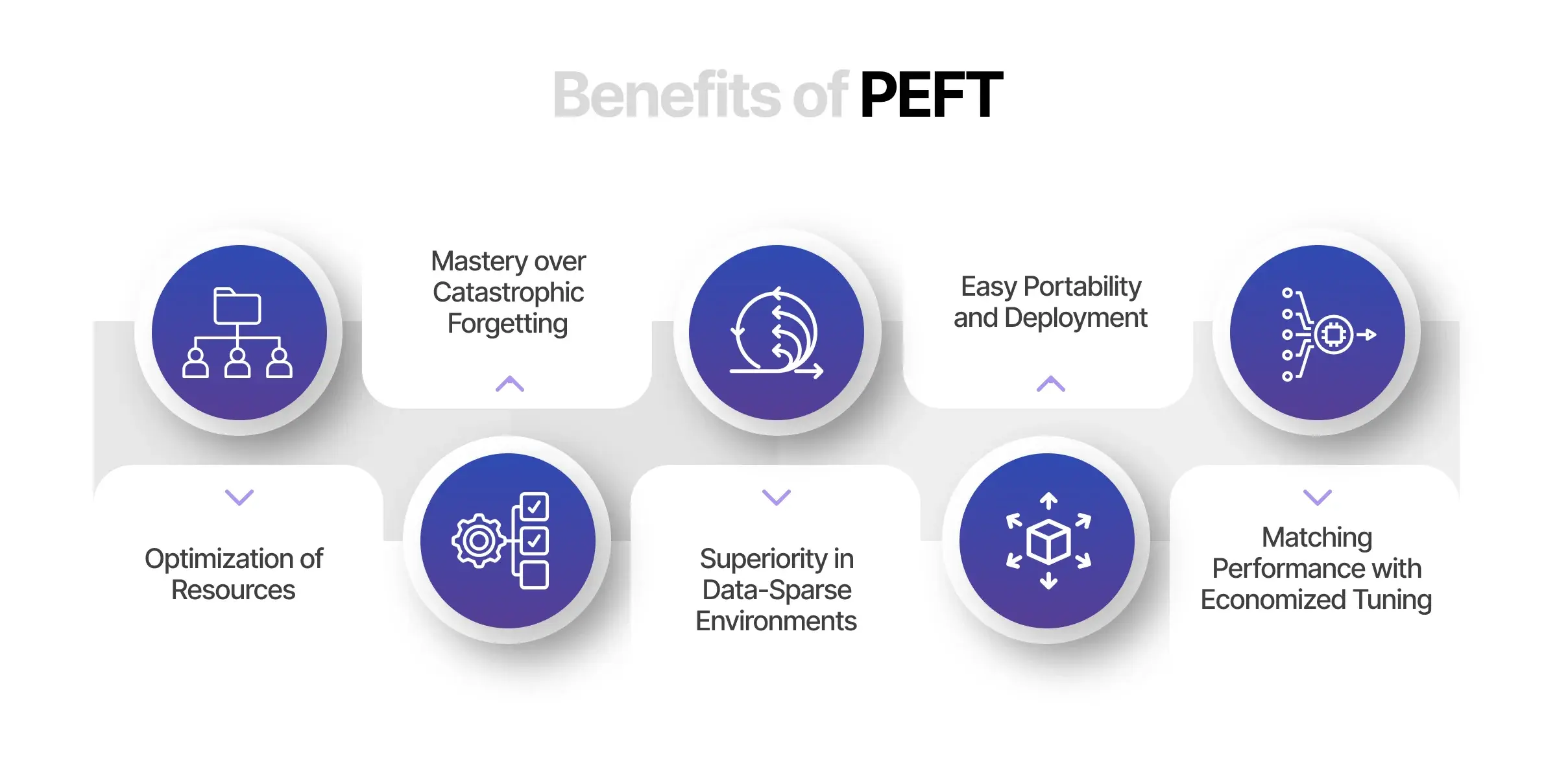
1. Resource Optimization through PEFT
Unlike traditional fine-tuning, PEFT strategically focuses on a limited subset of model parameters, keeping most pre-trained LLMs’ parameters intact. This streamlined process not only diminishes the computational power required but also significantly reduces the storage footprint. It’s akin to tuning a high-performance engine with meticulous precision rather than an exhaustive overhaul, achieving efficiency without compromising quality.
2. PEFT’s Mastery over catastrophic forgetting
One intriguing problem in full fine-tuning is the phenomenon known as catastrophic forgetting. This is when a model, in adapting to new tasks, inadvertently loses its previously acquired knowledge. PEFT deftly addresses this challenge by confining updates to a select few parameters. It’s akin to preserving the wisdom of experience while embracing the novelty of innovation, a balance that safeguards the model’s core intelligence.
3. Data-Sparse Environment Superiority with PEFT
Remarkably, PEFT’s prowess extends to low-data situations, where it has demonstrated an ability to outperform traditional full fine-tuning and show better generalization in out-of-domain applications. In addition, it operates like an agile startup within the vast corporate structure of machine learning, agile and adaptive in navigating uncharted territories.
4. Portability and Deployment Made Easy by PEFT
One of the unsung triumphs of PEFT is its ability to create compact checkpoints, a mere fraction in size compared to those generated through conventional fine-tuning. It’s like having a state-of-the-art technology lab that fits in a backpack. Consequently, this grants the freedom to mobilize and adapt across various tasks without cumbersome hardware or extensive modifications.
5. Performance Matching with Economized Tuning using PEFT
Perhaps the most compelling attribute of PEFT is its capability to rival the performance of full fine-tuning using only a minimal set of trainable parameters. Indeed, it is a testament to the brilliance of innovation that thrives on constraints, much like a space exploration mission that achieves stellar results with calculated resource allocation.
PEFT: Pioneering Precision Beyond Traditional Fine-Tuning
By adjusting models, one may reach higher precision and applicability, akin to stepping into the complex realm of artificial intelligence and machine learning. As a result, this paradigm change may be seen in PEFT (Precision Enhanced Fine-Tuning), which exceeds conventional fine-tuning methods’ limitations.
1. Targeted Adjustment
PEFT incorporates surgical accuracy in modification instead of the general method occasionally used in conventional fine-tuning. It ensures the underlying structure is neither overworked nor in danger by fine-tuning only the pertinent parameters. Variables are thoughtfully chosen to display elegance that is both fashionable and useful.
2. Intelligent Adaptation
The PEFT system is an example of an intelligent, adaptable system that accepts the complexity of the data without deviating from the task at hand. Instead of fine-tuning, which may force a model to match all applications, PEFT employs a flexible, task-specific optimization that enables models to flourish in niche applications.
3. Resource Efficiency
The architecture of PEFT is based on the efficient use of computer resources. Additionally, it drastically minimizes processing power and time by simply changing the relevant variables. This efficiency involves fundamentally rethinking those operations, not just a little resource allocation and consumption gain.
4. Unleashing New Possibilities
PEFT finds opportunities that conventional fine-tuning techniques might miss. Additionally, by customizing the modifications to each work’s unique requirements. It’s not just about doing the same thing faster; it’s also about finding new uses for technology and solutions that weren’t previously available or understood.
5. Future-Ready Approach
PEFT is a visionary strategy that anticipates the changing needs of a technology world that is changing quickly, not merely a step in the right direction. It serves as a testament to the never-ending quest for innovation and quality. Moreover, it denotes an adaptable, scalable, and stable position for the future.
The Process of Parameter Efficient Fine Tuning (PEFT)
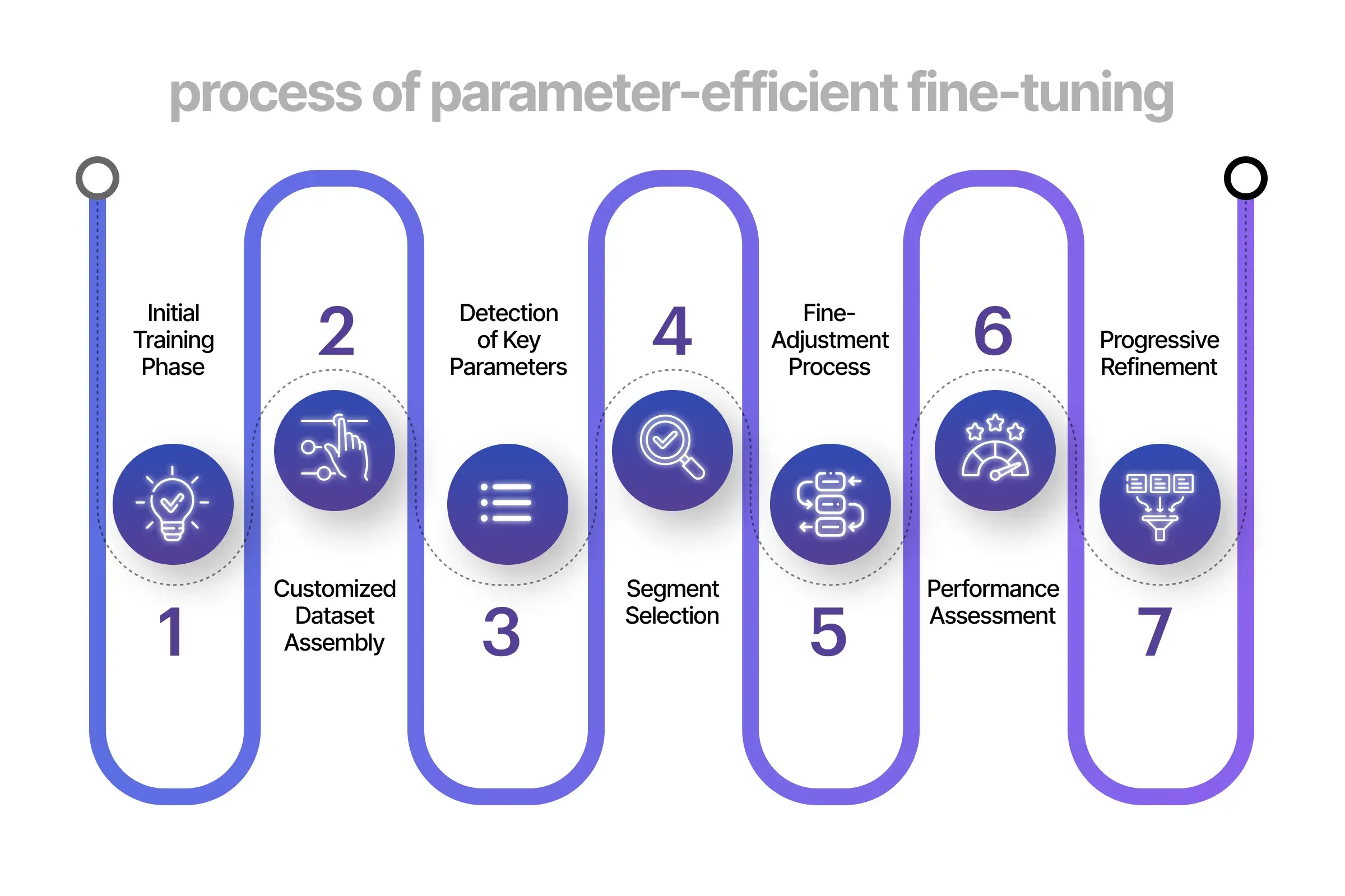
The approach for parameter-efficient fine-tuning might vary depending on the specific implementation and pre-trained model in use. Therefore, here is a broad outline of the PEFT methods involved:
1. Initial Training Phase
Start with a big model and pre-train it using a big data set for a general goal, such as language modeling or picture recognition. This basic training stage allows the model to identify important relationships and characteristics in the data.
2. Customized Dataset Assembly
Create or gather a dataset that is especially suited for the target job for which the pre-trained model will be adjusted. Thus, this collection must include appropriate labels and reflect the specific requirements of the intended job.
3. Detection of Key Parameters
Recognize or calculate the significance or applicability of parameters within the pre-trained model relating to the goal task. This phase is instrumental in deciphering which parameters warrant precedence during the fine-tuning process. Employing methodologies such as gradient-based techniques, sensitivity examination, or importance evaluation can facilitate the pinpointing of vital parameters.
4. Segment Selection
Choose a segment of the pre-trained model’s parameters according to their pertinence or significance to the goal task. Consequently, this segmentation can be governed by specific standards like a set threshold on the importance evaluations or cherry-picking the top most critical parameters.
5. Fine-adjustment Process
Activate the cherry-picked segment of parameters with the values originating from the pre-trained model. Meanwhile, immobilize the remaining ones. Subsequently, tailor the chosen parameters using the custom dataset. This encompasses training the model on the task-specific data employing advanced algorithms such as Stochastic Gradient Descent (SGD) or Adam optimization techniques.
6. Performance Assessment
Gauge the fine-tuned model’s efficacy on a validation dataset. Additionally, consider other suitable metrics resonating with the target task. Consequently, this evaluation is crucial in determining the success of PEFT in realizing the aspired performance with a minimized parameter count.
7. Progressive Refinement (Optional)
In line with the performance and necessities, there might be a choice to sharpen the PEFT process cyclically. This could involve modifying the standards for parameter choice, investigating diverse segments, or fine-tuning across extra cycles to enhance the model’s overall capability further.
Techniques to Enhance Fine-Tuning Efficiency in Computational Models
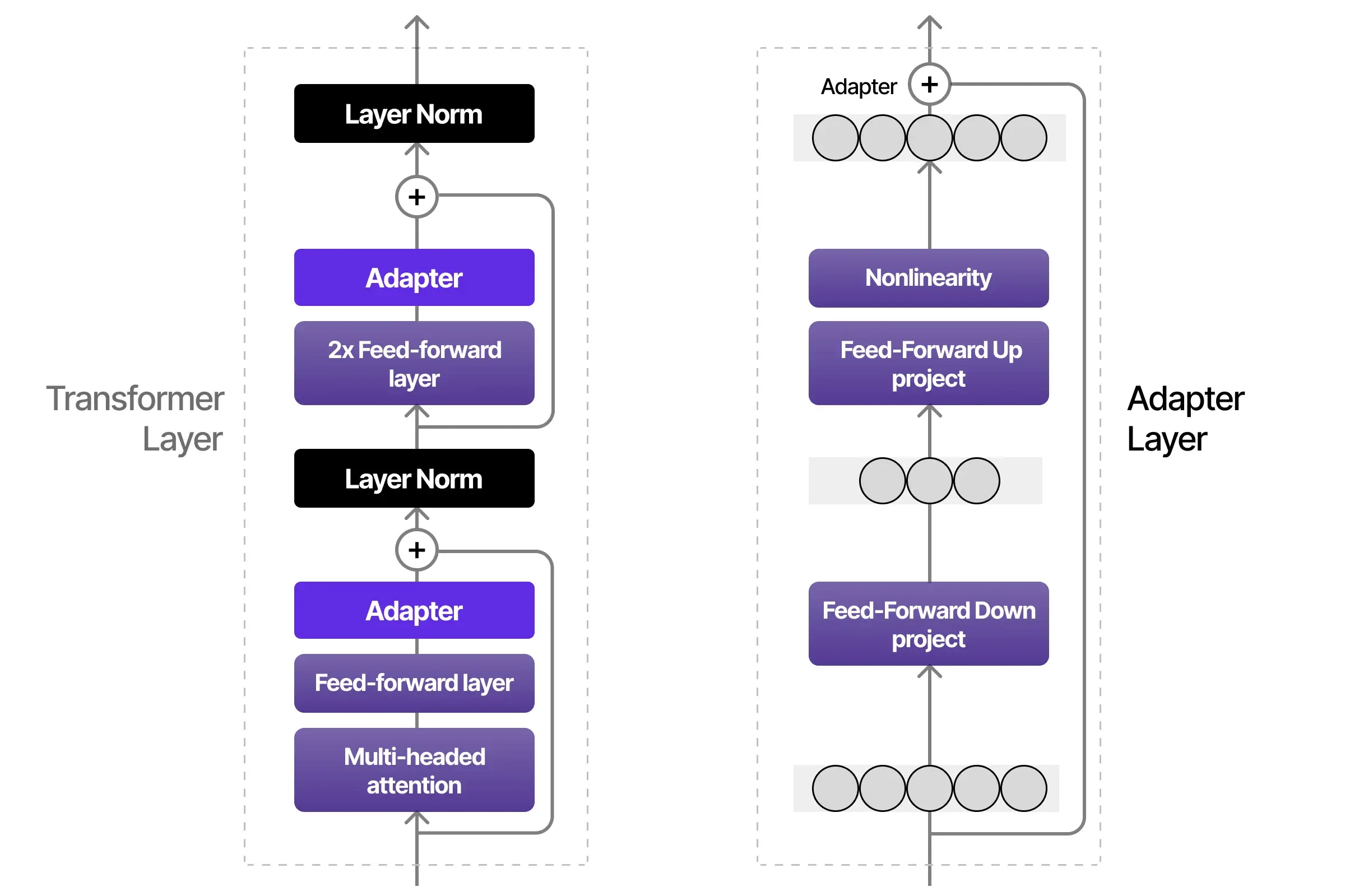
1. Adapter Methodology
The adapter technique, thus, presents a simple and modular machine-learning method that enables models to absorb fresh data. This method promotes learning without significantly changing the main model by inserting tiny neural network layers between already-existing levels. It’s a little adjustment that enables a less invasive adaptation of the existing network to new tasks. Additionally, it improves parameter consumption.
2. LoRA (Local Re-parameterization Algorithm)
The LoRA, or Local Re-parameterization Algorithm, introduces a creative method to re-parameterize a section of the pre-trained model. Moreover, it enhances the flexibility of model adaptation. LoRA tweaks localized factors rather than the entire design, enabling it to achieve particular objectives without using a lot of processing power. By enhancing models’ capacity for adaptability, this targeted approach makes them more versatile. It also makes them more effective at taking on new responsibilities.
3. Prefix Tuning Method
The prefix tuning technique is a cutting-edge strategy for sequence processing models. It significantly minimizes the difficulty of fine-tuning by just adjusting a fixed-length prefix in the input sequence. Moreover, this method stresses the alteration of a few key parts to grasp the work at hand. Additionally, Prefix tuning’s brilliance resides in its capacity to focus on the crucial without overly complicating the learning process.
4. Prompt Tuning Technique
Prompt tuning is a new method that looks at task-specific fine-tuning. Rather than changing the entire architecture, prompt tuning modifies the task prompts individually. This clever method works by extending or fine-tuning the embedded space that reflects the prompt. Consequently, this results in a more sophisticated job comprehension. Furthermore, it mainly preserves the original model, allowing for some specialization without spending a lot of processing resources.
5. P-Tuning (Pattern-Tuning) Method
The P-Tuning, or Pattern-Tuning, approach is a game-changing innovation in machine learning. Unlike previous approaches, which may need extensive revision, P-Tuning brings learnable patterns into the input space. These patterns are particular constructions that enable the model to grasp specific jobs thoroughly. Consequently, the model may be fine-tuned by altering these patterns, providing a flexible and focused approach without overwhelming computational needs.
Training Your Model Using PEFT
1. Importing essential dependencies and defining variables
By importing required libraries and modules, the code has access to the tools necessary to build and fine-tune the model:
Python
from transformers import AutoModelForSeq2SeqLM
from peft import PeftModel, PeftConfig
import torch
- from datasets import load_dataset
import OS
- from transformers import AutoTokenizer
- from torch.utils.data import DataLoader
- from transformers import default_data_collator, get_linear_schedule_with_warmup
- from tqdm import tqdm
- from datasets import load_dataset
Thus, these dependencies provide classes and functions needed for model development, data handling, tokenization, and training progress tracking.
Defining Variables
Variables such as dataset name, text column name, label column name, and batch size are crucial for managing data:
Python
dataset_name = “twitter_complaints”
text_column = “Tweet text”
label_column = “text_label”
batch_size = 8
Moreover, these variable definitions ensure the code’s adaptability to different datasets and training configurations.
2. Dataset and batch size configuration
This step aligns with the previous one but further elaborates on how the dataset and batch size are critical to the training process. A proper dataset ensures that the model has relevant information to learn from, and the batch size controls how many examples are processed simultaneously during training.
Pre-trained PEFT model and configuration loading
Identifying the pre-trained model is essential for later loading and fine-tuning:
python
peft_model_id = “smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM”
config = PeftConfig.from_pretrained(peft_model_id)
Thus, peft_model_id points to the specific model needed and config loads its unique settings, allowing for tailored training.
Maximum memory allocation
The code allocates specific memory quantities to different devices:
Python
max_memory = {0: “6GIB”, 1: “0GIB”, 2: “0GIB”, 3: “0GIB”, 4: “0GIB”, “cpu”: “30GB”}
This allows control over memory consumption, ensuring that no device is overburdened. Consequently, this prevents system crashes or slowdowns.
Base model loading
The pre-trained model is loaded into the code’s working environment:
python
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path, device_map=”auto”, max_memory=max_memory)
model = PeftModel.from_pretrained(model, peft_model_id, device_map=”auto”, max_memory=max_memory)
Furthermore, these lines load the base model and its weights into memory, preparing it for fine-tuning and modifications.
Data preprocessing
To make the dataset labels human-readable, underscores are replaced with spaces:
Python
classes = [k.replace(“_”, ” “) for k in dataset[“train”].features[“Label”].names]
This step is essential for ensuring clarity and comprehensibility when interpreting the model’s results.
Tokenization
Tokenization involves converting text data into numerical representations:
python
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
target_max_length = max([len(tokenizer(class_label)[“input_ids”]) for class_label in classes])
Moreover, this step is vital for preparing the text data for ingestion by the model, as it can only understand numerical inputs.
Dataset preparation for fine-tuning
The code snippet for preprocessing prepares the dataset for fine-tuning:
python
def preprocess_function(examples):
# Code for preprocessing
# …
train_dataset = processed_datasets[“train”]
eval_dataset = processed_datasets[“eval”]
test_dataset = processed_datasets[“test”]
Additionally, it organizes the data, ensuring the model receives the information in an understandable format.
Collate function definition and data loader creation
A collate function gathers and combines preprocessed examples:
Python
def collate_fn(examples):
return tokenizer.pad(examples, padding=”longest”, return_tensors=”pt”)
Therefore, this function helps manage data batches, ensuring efficient and effective model training.
Creating data loaders
Data loaders manage data flow during model training:
Python
train_dataloader = DataLoader(train_dataset, shuffle=True, collate_fn=collate_fn, batch_size=batch_size, pin_memory=True)
eval_dataloader = DataLoader(eval_dataset, collate_fn=collate_fn, batch_size=batch_size, pin_memory=True)
test_dataloader = DataLoader(test_dataset, collate_fn=collate_fn, batch_size=batch_size, pin_memory=True)
These loaders allow seamless transitioning between batches, optimizing the training process.
3. Model training and evaluation
Training specifications
Model training requires specifications like the number of epochs and loss function:
python
# Training code
Model Evaluation
Evaluating the model’s performance on a test dataset ensures that it performs well:
python
model.eval()
# Evaluation code
Performance Assessment
This step evaluates the model’s accuracy and other metrics on a specific dataset. Moreover, detailed methods can be found in associated documentation or on GitHub.
How Markovate Can Help?
In the fast-paced, ever-evolving world of Artificial Intelligence and Machine Learning. Markovate thrives as an AI development company specializing in harnessing the power of Large Language Models (LLMs) such as GPT, T5, and BERT. Moreover, with an adept understanding of innovations like Parameter-Efficient Fine-tuning (PEFT), Markovate goes beyond standard practices to deliver highly optimized models for specific applications without overburdening ordinary consumer-grade hardware. We provide affordable, effective, and specialized solutions. Specifically, these align with your particular company’s demands by utilizing cutting-edge methodologies like Adapter Methodology, LoRA, and Prompt Tuning.
We ensure that our clients take advantage of the most recent technical developments. Moreover, thanks to our expertise in NLP, computer vision, and auditory processing. Furthermore, Markovate’s systematic approach to model adaption and tweaking demonstrates our dedication to clever engineering and ingenuity. Additionally, we know the costs and difficulties associated with deploying fine-tuned models, and we work to solve them using a cutting-edge computational architecture similar to reusable rocket technology. Our knowledgeable team of professionals highly values thoughtfulness and client-centeredness. As a result, we strive to combine performance with cost-effective tuning and opening up fresh opportunities in artificial intelligence. Consequently, Markovate’s committed efforts pave the way for a future in which the gap between machine learning and human talent continues to close, opening up new vistas for technological brilliance.
Conclusion
Parameter Efficient Fine-Tuning is revolutionizing the way we train machine learning models by offering a more efficient, cost-effective alternative to traditional fine-tuning methods. By targeting specific parameters and utilizing advanced techniques, PEFT optimizes model performance without the need for extensive computational resources.
This approach not only enhances precision but also provides scalable solutions for real-world applications. As we continue to explore its potential, PEFT stands as a key innovation in advancing machine learning practices. With the right tools and expertise, like those provided by Markovate, businesses can harness PEFT to unlock new possibilities in AI development.
FAQs
1. What is Parameter Efficient Fine Tuning (PEFT)?
With a clever twist, PEFT is similar to fine-tuning. Unlike traditional approaches that adjust all parameters, PEFT concentrates exclusively on the most important factors. It’s similar to modifying an automobile’s engine rather than completely rebuilding it. Model training becomes more effective and exact as a result of the time and resource savings.
2. Why is PEFT Important in Machine Learning?
Consider PEFT to be the greener alternative to model training. It works effectively even when there is less data, consumes fewer resources, and reduces the danger of overfitting. Because of this, it is simpler to use and ideal for the modern, quick-paced computer environment.
3. What Techniques are used to make Fine-tuning more Efficient?
Increasing the effectiveness of fine-tuning is similar to adding tools to your toolbox. Similarly, the unique tools that assist in modifying models without going overboard include the Adapter Method, LoRA, Prefix Tuning, and P-tuning. Each approach focuses on a certain region, resulting in a versatile and effective manner to complete the task. Therefore, working smarter, not harder, is the key.