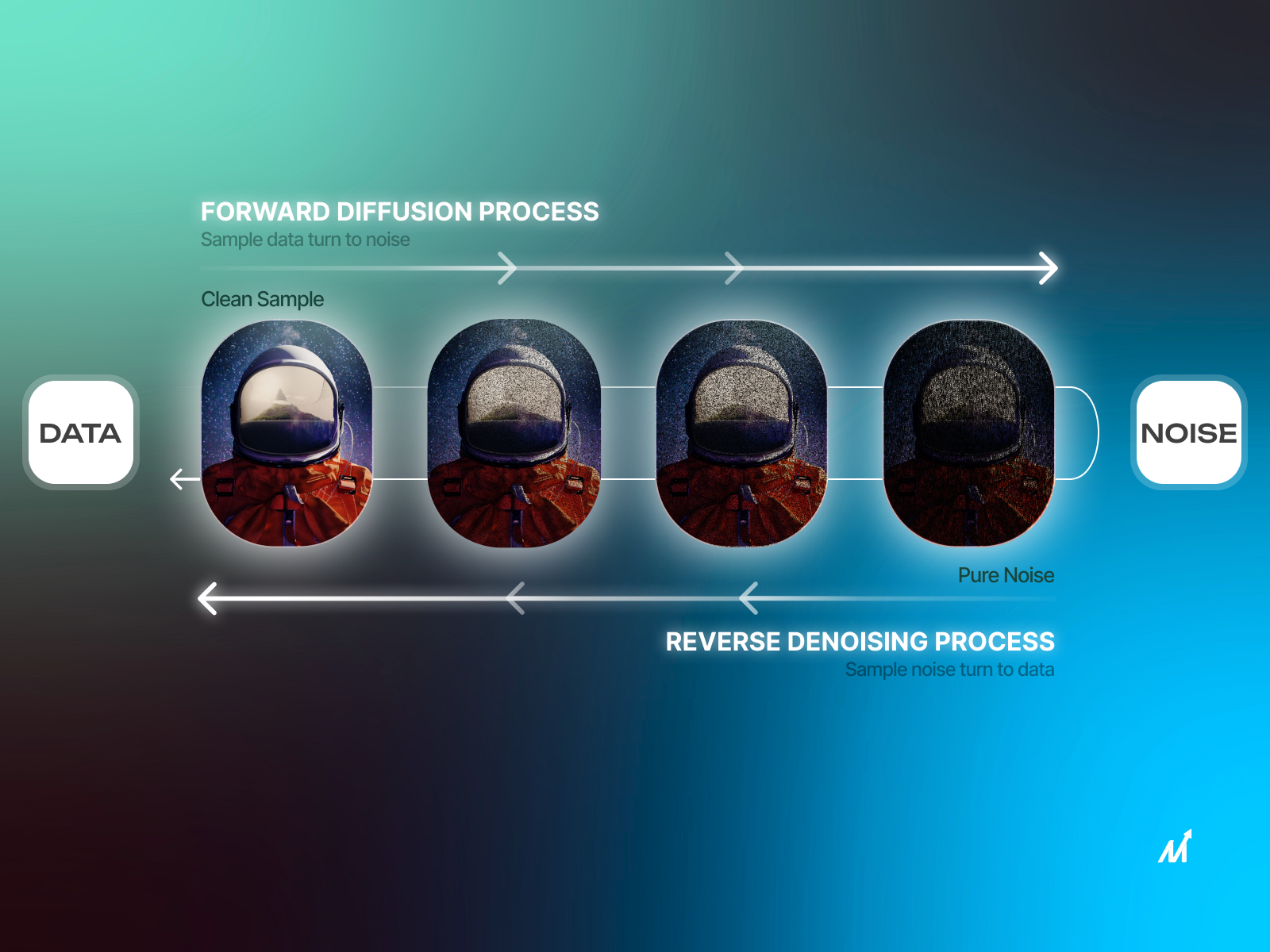
Over the past 20 months, creators and enthusiasts of generative AI and GPT 4 have been captivated by the remarkable capabilities of diffusion models. The once impossible task of transforming text into images has become a reality, thanks to the fantastic advancements in stable diffusion models. Consequently, there has been an astounding surge in the utilization and generation tailoring the Diffusion Models for Brand Success of AI-powered images, with organizations embracing this technology on a large scale. Customized diffusion models have turned an essential stake in business processes as they can cater to the personalized requirements of enterprises. Fortunately, we are here to guide you through the intricacies of diffusion models, their functionality, and the seamless training process that enables them to align perfectly with your brand.
Unleashing the Potential of Diffusion Models and Diffusion AI
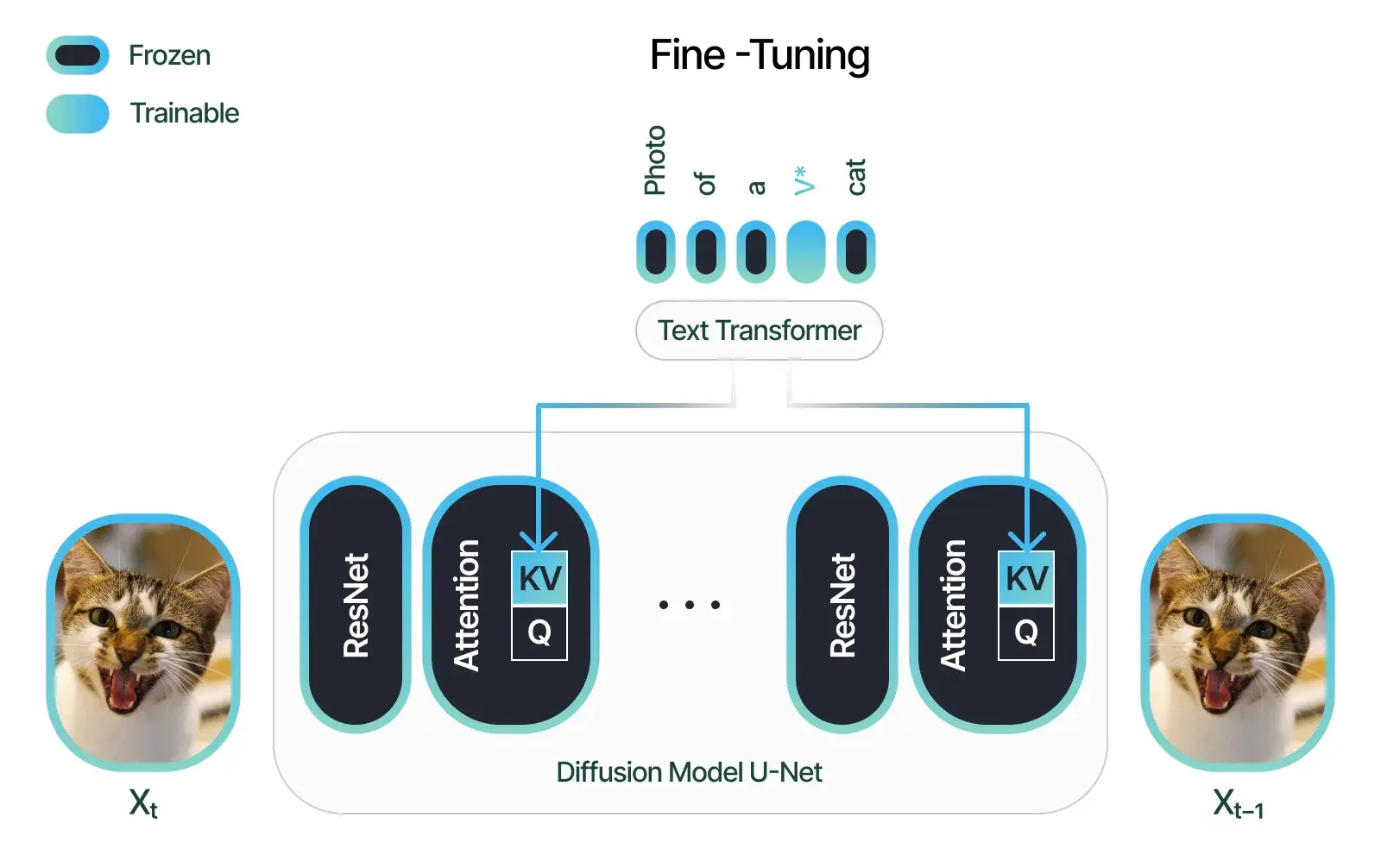
At its essence, diffusion models can generate data that closely resembles the examples they have been trained on. For instance: Imagine teaching a diffusion model with specific metrics to produce floor plans. Once trained, it generates similar projects based on the given metrics proficiently. However, Diffusion AI represents a dynamic amalgamation of artificial intelligence (AI) advancements in diffusion modeling, facilitating the widespread adoption and dissemination of these models across diverse industries and communities.
Recent research by Jonathan reveals that a diffusion model, or a probabilistic diffusion model, is a parameterized Markov chain trained using variational inference. This training process enables the model to generate samples aligned with the observed data within a finite timeframe. In other words, these models employ mathematical frameworks to define and transition between states over time, guided by the probabilities derived from the acquired data and past experiences. As a result of recognizing patterns in recent data, diffusion models often exhibit the capacity to make plausible predictions.
How does stable diffusion models work?
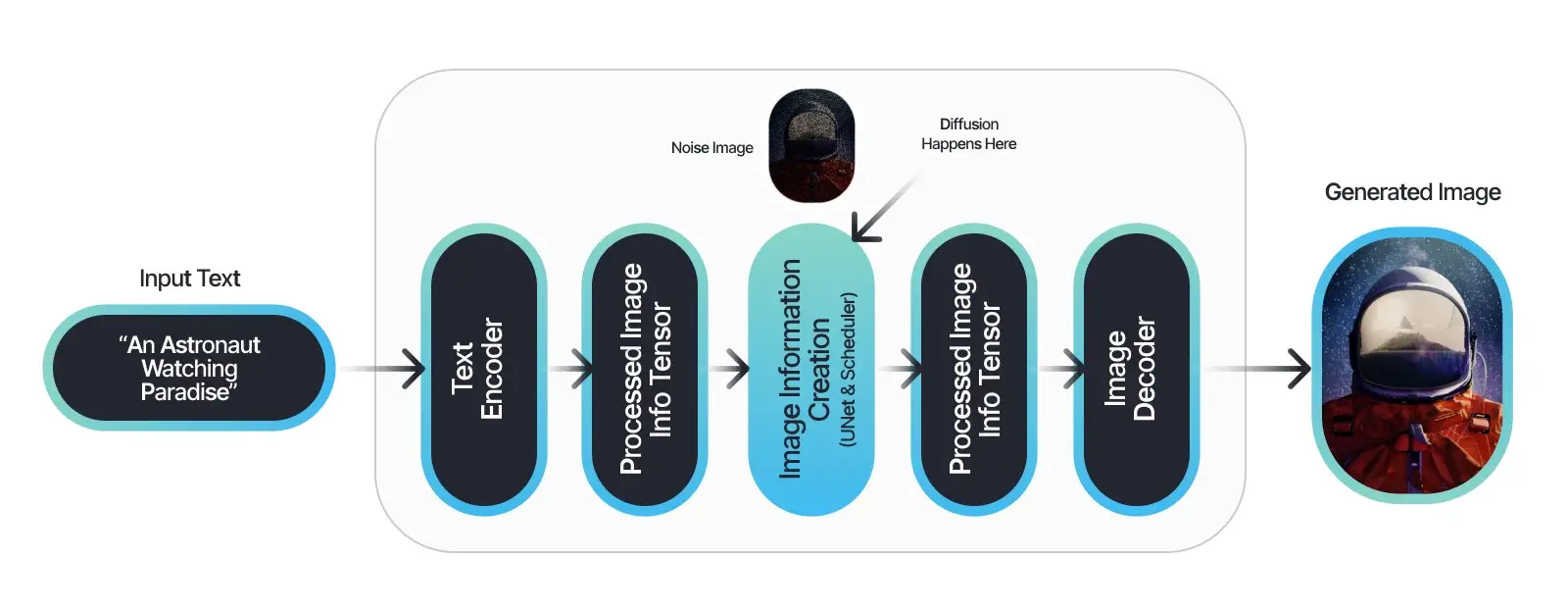
The stable Diffusion Model is a distinctive latent diffusion model that operates specifically within the high-dimensional image space through an initial compression of the images. This compression step significantly enhances its computational efficiency. What sets the Stable Diffusion Model apart is its approach to corrupting image data, as it avoids traditional methods of noise addition and instead generates random tensors within the latent space.
This unique approach is based on the principles of the variational autoencoder technique, encompassing three crucial phases: encoder, latent space, and decoder. By creatively and professionally rephrasing the given passage, the revised description highlights the innovative aspects and technical intricacies of the Stable Diffusion Model.
Essential Factors in crafting superlative Diffusion Models: An Evaluation Framework
We are presented with a variety of diffusion models to consider. In addition, several associated techniques can influence the outcome. Consequently, it becomes crucial to evaluate the diffusion models thoroughly. Let us now delve into a comprehensive analysis of these models:
Refinement: Estimating the Fine-tuned Quality
Assessing the quality of fine-tuning involves examining the smoothness and reliability of the diffusion model at a fundamental level. The model’s ability to function with minimal adjustments and a higher degree of automation is crucial. Consequently, the fine-tuning capability can be evaluated by considering two main factors:
- How similar is the output to the input object, and
- How aesthetic the value of the image is.
Assessing for Similarity
The primary objective of diffusion models is to comprehend the essential attributes of the actual input. And reproduce them faithfully in the output. Users seek to generate similar objects or faces in various contexts, situations, and artistic styles. The model’s proficiency lies in effectively communicating all these characteristics across its outputs. This proficiency is contingent upon its adeptness in face cropping and embedding capabilities.
Reviewing face-cropping Capabilities
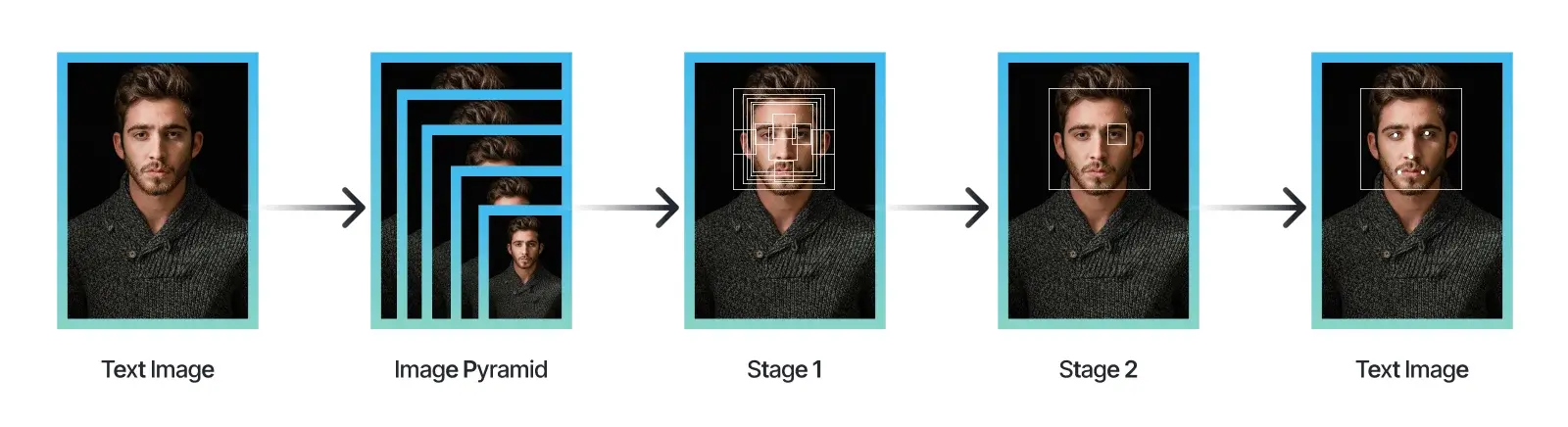
The diffusion model examines the properties of a face or object within a specific framework. Enterprises must guarantee the reliability of the underlying architecture. An exemplary instance of such a dependable architecture is MTCNN, which employs a multi-step approach. This process involves the selection of multiple bounding boxes followed by the precise determination of landmarks of essential facial areas, such as the eyes, corners of the mouth, and nose.
Analyzing Face Embedding Capabilities
Face cropping involves precisely detecting and isolating the object or face within an image. On the other hand, embedding refers to the technique employed by the model to encode the output consistently and reliably, enabling effective comparison. In the context of diffusion models, the objective is to abstract images into vector representations, facilitating their utilization in generating multiple images while aiming to achieve the highest possible similarity score.
The Foundation of Customizing Stable Diffusion Models Explained
Before commencing the training of the diffusion models, it is essential to establish the necessary setup. A foundational step in this process entails defining several parameters, which include:
- The token name serves as a distinctive identifier that will be used to refer to the subject we intend to include. This name must be unique, ensuring we do not conflict with existing representations.
- Class Name enhances the effectiveness of the motivation section by enabling the model to accurately identify objects within various classes, such as individuals, animals, or other things. Additionally, one can utilize to identify specific celebrities in certain scenarios.
- Regularization images refer to the training images used to train a model for a specific parameter. Typically, one can employ 200 images per prompt to enhance the quality of outcomes. This practice prevents overfitting and minimizes language drift, promoting more accurate and reliable model performance.
- Training iterations, as the term implies, refer to the number of times the model undergoes a refinement process to enhance its capabilities. Determining the appropriate number of iterations requires careful consideration, as excessively high values can result in overfitting problems. As a general guideline, a range of 100 to 200 iterations is commonly employed. Although, this number may adjust according to specific requirements.
Three Pillars of Diffusion Models
Diffusion models are built on three core mathematical frameworks, each employing techniques to inject and then eliminate noise to create fresh samples. Let’s delve into these foundational categories.
1. Denoising Diffusion Probabilistic Models (DDPMs)
DDPMs serve as generative models specifically designed for cleaning up noisy visual or auditory data. Their track record is commendable, with applications ranging from various image to sound restoration tasks. For example, the movie-making business relies on cutting-edge visual and auditory processing software to elevate their production standards.
2. Score-Guided Noise-Influenced Generative Models (SGMs)
SGMs have the capability to spawn new samples originating from a specified distribution. These models master a scoring function that approximates the log density of the intended distribution. This log density approximation presumes that available data points are fragments of an unidentified dataset or test set. Utilizing this scoring function, SGMs can then birth new data points that belong to that distribution. Case in point, while Generative Adversarial Networks (GANs) get most of the limelight for generating deepfake videos, SGMs have demonstrated a parallel, if not superior, proficiency in synthesizing high-definition images of celebrities. Additionally, SGMs play a role in broadening healthcare datasets, generally restricted due to rigorous industry norms and guidelines.
3. Stochastic Differential Equations (SDEs)
SDEs map out the evolutionary trajectory of random processes as they unfold over time. These equations find extensive applications in sectors like physics and financial markets, where unpredictability plays a significant role. For example, commodity prices are volatile and subject to multiple random influences. SDEs are adept at determining financial derivatives such as future contracts (e.g., crude oil contracts) by modeling this volatility. This enables precise price prediction, offering a layer of fiscal assurance.
How Can you Make Stable Diffusion Models Distinctive?
It is essential to follow the following steps to create a customized and tailored diffusion models for an enterprise:
- Segregating the data into training and test sets
- Employing proper model parameters
- Conditional and unconditional training
In the preceding paragraphs, we have delved into segregation and parameters. Now, let us explore the steps employed in training the model to imbue it with distinctiveness:
- Single concept training: The training process may commence by selecting a subset of recommendations containing fewer images. This initial step fine-tunes the fundamental aspects and ensures the model acquires novel features before engaging in more advanced training procedures.
- Multi-concept training: In preparation for tackling complex tasks, the diffusion model undergoes simultaneous and collaborative training with multiple parameters. The model utilizes modifier tokens assigned to each to distinguish between these parameters. The current diffusion model can handle various concepts while incurring a minimal loss of functionality.
- The demonstration phase thoroughly tests the custom diffusion model’s capabilities by providing a gradient space and sample code. This stage assesses the results and determines whether the model has reached a refined state suitable for implementation. Additional iterations of the preceding steps are executed if further refinement is necessary before proceeding to another demonstration.
- Setting up: Here, the custom diffusion repository is cloned and installed. Later, you can add any essential plugins to prepare it for immediate commercial use.
Hugging Face Stable Diffusion Model for Optimal Results
HuggingFace, the leading AI community, builds open-source tools for creating, training, and deploying machine learning models. Its renowned transformers library offers a user-friendly Python API for cutting-edge NLP tasks. It facilitates the seamless sharing of resources among practitioners. Leveraging the Stable diffusion offered by Hugging Face can give enterprises several advantages. Here are some ways in which it can benefit:
- The license is not strict and doesn’t need acceptance through UI.
- The platform and code are open source, making it a safer, easier, and more reliable source to clone.
- Previous iteration works from other models in the recent past can be used for professional and tailor-made customization; its vast library is added advantage.
- Hugging Face employs intel hardware to boost AI workloads.
How Markovate builds you the best stable diffusion Models?
Markovate is a prominent team of developers that excels in providing dependable services related to the Stable Diffusion Models. Hire our team of stable diffusion developers comprised of skilled AI scientists who diligently incorporate the latest models and updates to crafting cutting-edge solutions tailored to meet the demands of businesses. Contact us to leverage our expertise to uplift you in various crucial domains, which include:
- Stable Diffusion Model Custom Development: We utilize advanced tools and techniques in deep learning and machine learning to build custom Stable Diffusion powered models. Our AI engineers create accurate and reliable models for successful data-driven outcomes.
- Stable Diffusion AI Consulting: Our experienced team provides AI development consultation, specifically on Stable Diffusion AI models, to help you integrate them effectively into your existing operations. We analyze your needs and offer guidance to plan and manage an AI solution aligned with your goals.
- Stable Diffusion Models Integration: Our integrated Stable Diffusion model service covers end-to-end deployment, including model selection, integration, testing, and secure implementation. Our skilled AI team excels in predicting behaviors across complex systems, delivering effective AI-powered solutions.
- Stable Diffusion Support: We offer professional technical support and maintenance services for Stable Diffusion. Our priority is to keep your systems and AI solutions running smoothly. It will ensure uninterrupted operation and safeguarding against technical issues and data breaches.