Advanced RAG Techniques stand at the cutting edge of artificial intelligence, transforming how machines understand and interact with human language. These sophisticated methods are not just about making smarter chatbots or more intuitive search engines; they’re reshaping our expectations of technology. By integrating vast amounts of external knowledge seamlessly, advanced retrieval-augmented generation (RAG) systems offer a glimpse into an AI-powered future where answers are not just accurate but contextually rich.
The leap from basic models to these advanced techniques marks a significant evolution in the field of AI. This comes after years of digging deep and building from the ground up to push past old hurdles – think short attention spans or hit-and-miss facts finding – that used to trip up how machines get what we’re saying.
Understanding Retrieval-Augmented Generation (RAG)
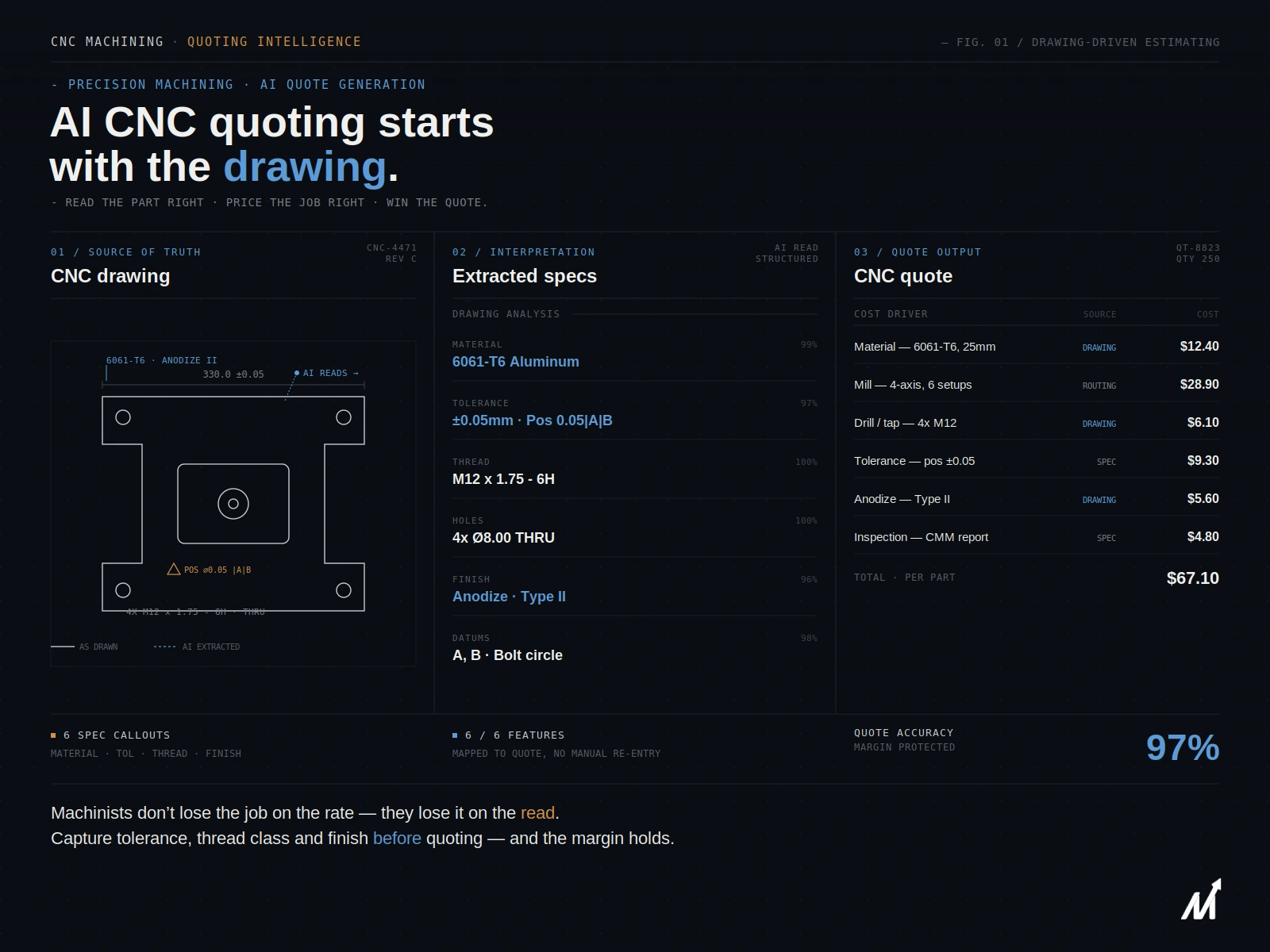
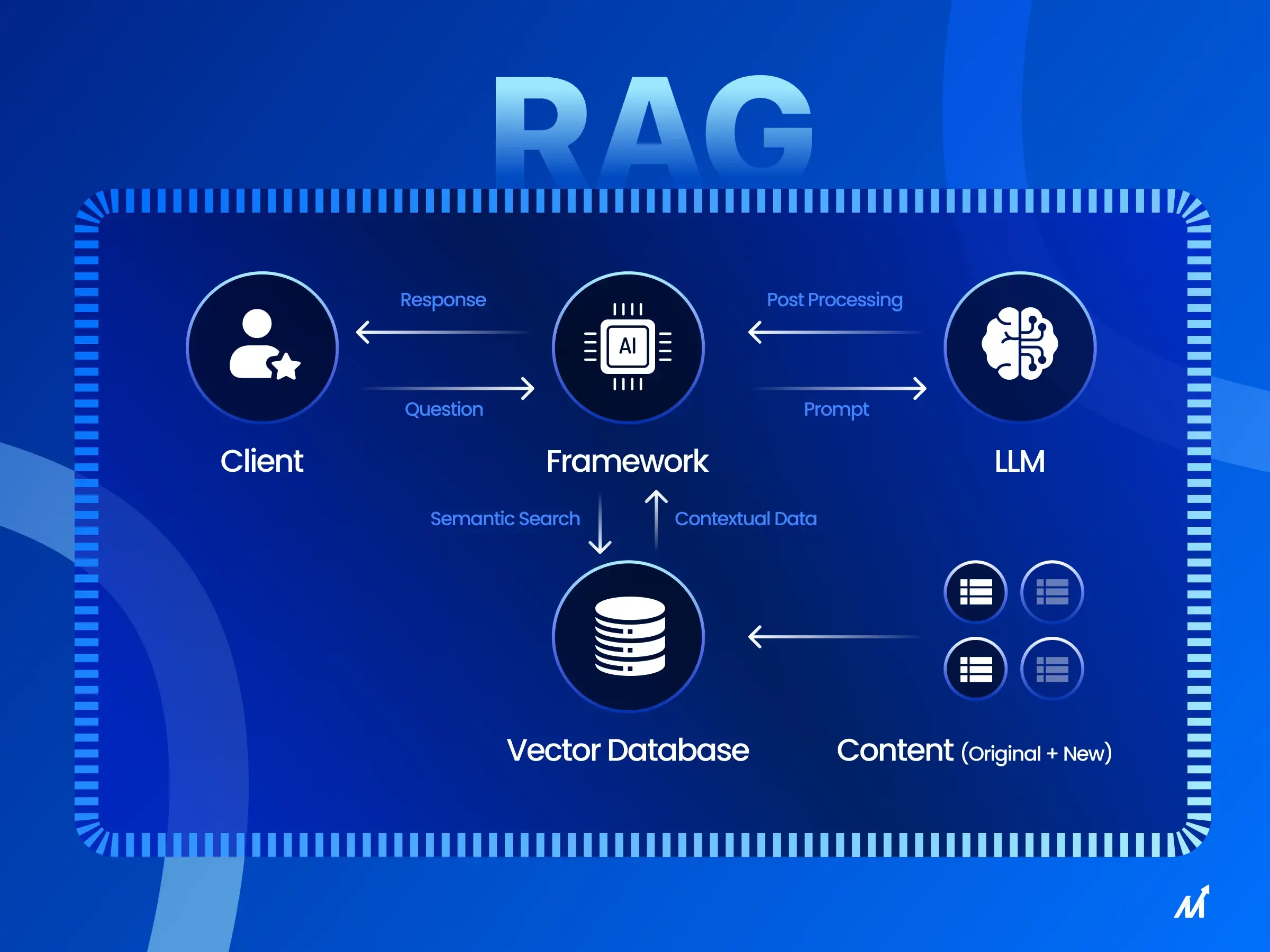
Retrieval-augmented generation (RAG) is a powerful technique that combines the strengths of traditional language models with the vast knowledge stored in external databases. It’s a game-changer in the world of AI and natural language processing.
RAG systems differ from traditional language models in their ability to access and utilize information from a much larger pool of knowledge. This allows them to generate more accurate, relevant, and contextually rich responses to user queries.
In practice, the RAG retrieval process uses embeddings and vector search to locate the most relevant data from external knowledge bases, ensuring that only high-quality retrieved information is passed to the language model for response generation.
RAG vs. Traditional Language Models
Traditional language models rely solely on the information stored in their parameters during training. While this allows them to generate coherent text, they are limited by the knowledge they were exposed to during the training process.
RAG, on the other hand, can access external knowledge bases during the generation process. This means that RAG models can draw upon a vast array of information to inform their outputs, leading to more accurate and informative responses.
The Role of Vectors and Vector Databases
Vector databases are a crucial component of RAG systems. They enable efficient retrieval of relevant documents by representing both the user query and the documents in the knowledge base as high-dimensional vectors.
The similarity between these vectors can be quickly calculated, allowing the RAG system to identify the most relevant documents to the user’s query. This process, known as vector search, is much faster and more scalable than traditional keyword-based search methods.
Retrieval Systems in AI Applications
Retrieval systems are becoming increasingly important in a wide range of AI applications. From question-answering systems to chatbots and content-generation tools, the ability to quickly access and utilize relevant information is essential.
RAG techniques are particularly well-suited to applications that require access to large amounts of external knowledge. By leveraging the power of vector databases and advanced retrieval techniques, RAG systems can provide more accurate and informative responses to user queries.
As the demand for intelligent, knowledge-driven AI systems continues to grow, retrieval systems and RAG techniques will likely play an increasingly important role in the development of cutting-edge AI applications.
Types of RAG Architectures
Several different approaches to building RAG systems exist, each with its own strengths and weaknesses. In this section, we’ll explore three of the most common RAG architectures: Naive RAG, Advanced RAG, and Modular RAG.
Naive RAG
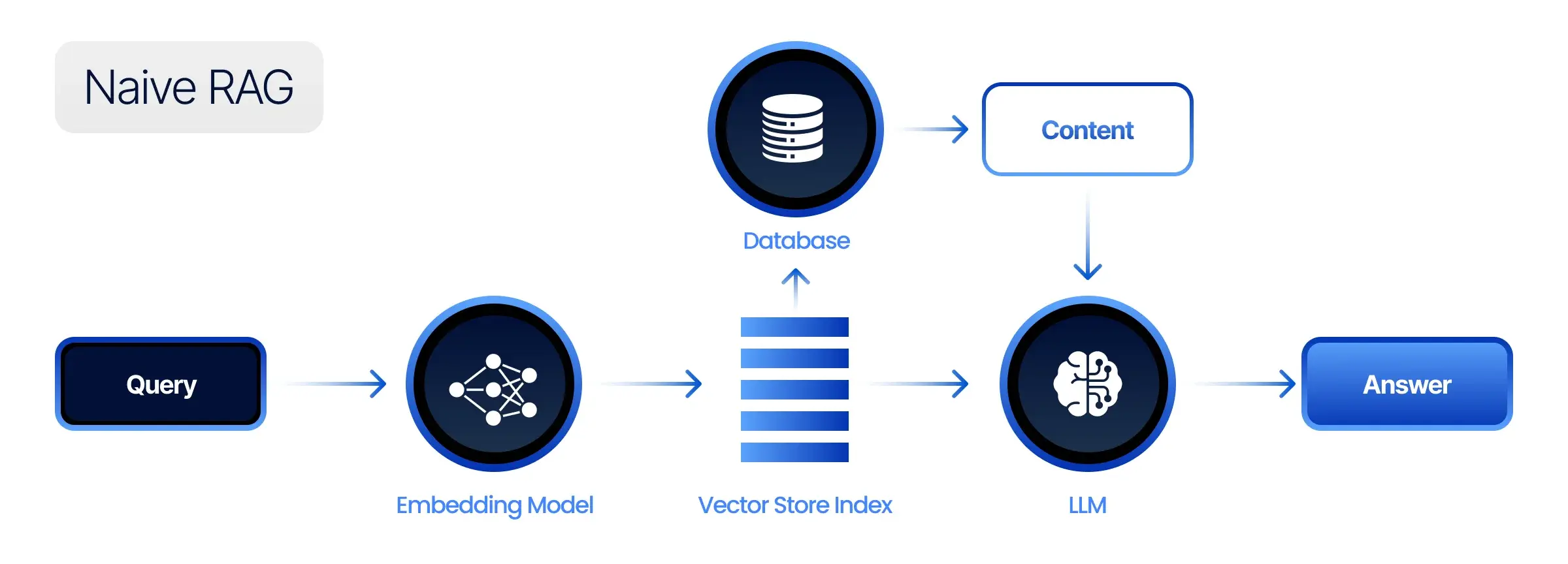
Naive RAG is the simplest approach to building a RAG system. In this architecture, the model retrieves a fixed number of documents from the knowledge base based on their similarity to the user’s query. These documents are then concatenated with the query and fed into the language model for generation.
While Naive RAG can be effective for simple queries, it has some limitations. The fixed number of retrieved documents can lead to either insufficient or excessive context, and the model may struggle to identify the most relevant information within the retrieved documents.
Advanced RAG Techniques
Advanced RAG techniques aim to address the limitations of Naive RAG by incorporating more sophisticated retrieval and generation mechanisms. These may include query expansion, where additional terms are added to the user’s query to improve retrieval accuracy or iterative retrieval, where the model retrieves documents in multiple stages to refine the context.
Advanced RAG systems may also employ techniques like attention mechanisms to help the model focus on the most relevant parts of the retrieved documents during generation. By selectively attending to different aspects of the context, the model can generate more accurate and contextually relevant responses.
Modular RAG Pipelines
Modular RAG pipelines break down the retrieval and generation process into separate, specialized components. This allows for greater flexibility and customization of the RAG system to suit specific application needs.
A typical modular RAG pipeline might include stages for query expansion, retrieval, reranking, and generation, each handled by a dedicated module. This modular approach allows for the use of specialized models or techniques at each stage, potentially leading to improved overall performance.
Modular RAG pipelines also make it easier to experiment with different configurations and identify bottlenecks or areas for improvement within the system. By optimizing each module independently, developers can create highly efficient and effective RAG systems tailored to their specific use case.
Key Takeaway:
RAG techniques supercharge AI by pulling information from vast knowledge bases, making responses smarter and more on-point. From simple to modular setups, they tailor answers with precision, transforming how machines understand us.
Optimizing RAG Performance
Optimizing the performance of an RAG system is crucial for delivering accurate and relevant responses to user queries. Several techniques can be employed to enhance retrieval accuracy, response quality, and overall system efficiency.
Sentence-Window Retrieval
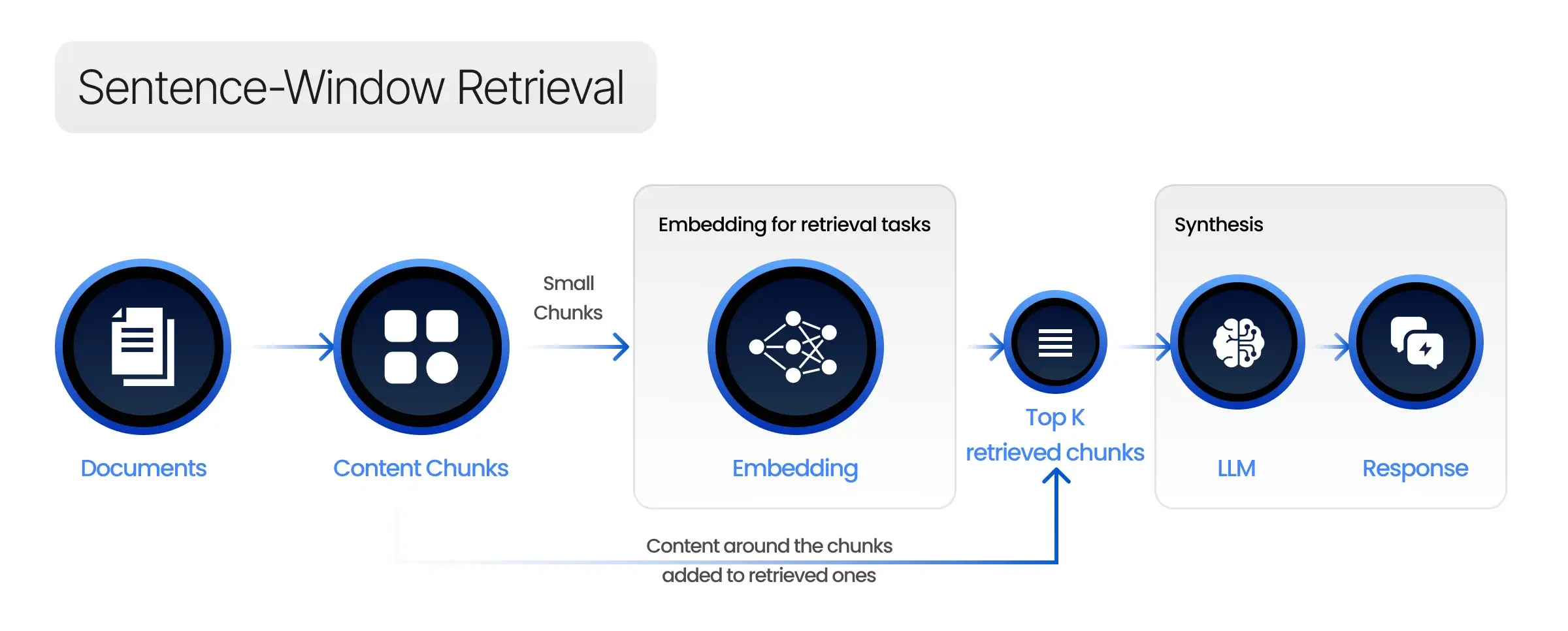
Sentence-window retrieval focuses on retrieving smaller, more relevant chunks of text, such as individual sentences or short passages, rather than entire documents. This approach helps reduce noise and improve the relevance of the retrieved context, ultimately leading to more accurate generated responses.
By breaking down the document retrieval process into smaller units, the RAG system can better identify the most pertinent information for answering the user’s query. This method is particularly effective for handling complex queries that require specific details or facts.
Retriever Ensembling and Reranking
Retriever ensembling involves combining multiple retrieval models to improve overall retrieval accuracy. By leveraging the strengths of different retrieval approaches, such as BERT or semantic search, the RAG system can more effectively identify the most relevant documents. This process helps improve the quality of search results, ensuring that users receive accurate and contextually appropriate answers.
Reranking techniques are then applied to further refine the retrieved results based on additional criteria, such as relevance scores or diversity. This ensures that the most informative and diverse set of documents is selected for the subsequent response generation stage.
Response Generation and Synthesis
Response generation in RAG systems involves integrating the retrieved context with the original user query to produce a coherent and informative answer. Advanced prompt engineering techniques, combined with attention mechanisms and content planning, are employed to focus on the most relevant parts of the retrieved text and ensure a logical flow of information in the generated response. Filtering out irrelevant context ensures that the model focuses only on meaningful information, improving grounding and logical consistency.
By leveraging the power of large language models (LLMs), RAG systems can synthesize the retrieved information into a natural and contextually relevant response. This sophisticated approach enables RAG systems to handle a diverse range of reasoning tasks and provide accurate answers based on the available knowledge.
Knowledge Refinement
Knowledge refinement techniques aim to improve the quality and relevance of the information retrieved by the RAG system. This can involve methods such as entity linking, which identifies and disambiguates named entities within the retrieved context, and knowledge graph integration, which incorporates structured knowledge to enhance the retrieval process.
By refining the retrieved knowledge, RAG systems can provide more precise and informative responses to user queries. This is particularly important for domains that require a high level of accuracy, such as healthcare or finance, where the reliability of the generated answers is critical.
Implementing Advanced RAG with LlamaIndex and LangChain
LlamaIndex and LangChain are two popular open-source libraries that offer powerful tools for building advanced RAG systems. These libraries provide a range of features and optimizations to streamline the development process and improve the performance of RAG applications.
Indexing Optimization
LlamaIndex offers various indexing techniques to optimize the retrieval process in RAG systems. One such technique is hierarchical indexing, which organizes the knowledge base into a tree-like structure, enabling faster and more efficient retrieval of relevant documents.
Another indexing optimization available in LlamaIndex is vector quantization, which compresses the vector representations of documents to reduce storage requirements and improve search speed. By leveraging these indexing optimizations, developers can build scalable RAG systems capable of handling large knowledge bases.
Retrieval Optimization
LangChain provides a flexible and modular framework for building retrieval pipelines in RAG systems. It offers a wide range of retrieval techniques, such as semantic search and query expansion, which can be easily integrated and experimented with to optimize retrieval performance.
LangChain also supports integration with popular vector databases, such as Pinecone and Elasticsearch, enabling efficient storage and retrieval of vector representations. By leveraging LangChain’s retrieval optimization capabilities, developers can fine-tune their RAG systems to achieve high retrieval accuracy and efficiency.
Post-Retrieval Optimization
Post-retrieval optimization techniques focus on refining the retrieved information before passing it to the response generation stage. LlamaIndex offers methods such as relevance feedback, which allows the RAG system to iteratively refine the retrieval results based on user feedback, improving the relevance of the retrieved context over time.
Another post-retrieval optimization technique is information filtering, which removes irrelevant or redundant information from the retrieved text. By applying these optimizations, RAG systems can provide more concise and targeted responses to user queries.
CRAG Implementation
Corrective Retrieval-Augmented Generation (CRAG) is an advanced RAG technique that aims to improve the factual accuracy of generated responses. CRAG works by iteratively retrieving and integrating relevant information from the knowledge base to correct and refine the generated output.
LlamaIndex provides an implementation of CRAG, which has shown promising results on benchmarks such as the MTEB leaderboard. By leveraging CRAG, developers can build RAG systems that generate more accurate and reliable responses, even for complex queries that require multiple retrieval steps.
Building Graphs with LangGraph
LangGraph is a library that extends LangChain to support the construction of knowledge graphs for RAG systems. By representing the knowledge base as a graph, LangGraph enables more sophisticated retrieval and reasoning capabilities, such as multi-hop retrieval and graph-based inference.
This approach is particularly useful for tasks that require complex reasoning over multiple pieces of information. With LangGraph, developers can build RAG systems that can navigate and extract insights from interconnected knowledge, opening up new possibilities for advanced question-answering and knowledge discovery.
Key Takeaway:
Boost your RAG system’s performance by focusing on targeted retrieval, combining models for accuracy, and refining responses with advanced techniques. Use tools like LlamaIndex and LangChain to optimize at every step, ensuring more precise answers.
Addressing Limitations of Naive RAG Pipelines
One of the main limitations of Naive RAG pipelines is the potential for retrieval errors, where the model fails to identify the most relevant information for a given query. To address this, researchers have explored techniques such as query expansion, where the original query is augmented with additional terms to improve the retrieval accuracy, and semantic search, which goes beyond keyword matching to capture the underlying meaning of the query.
These techniques often involve a deep dive into the knowledge base, leveraging graph databases and advanced indexing methods to enable more sophisticated retrieval strategies. By improving the quality of the retrieved documents, these approaches can significantly enhance the overall performance of the RAG system.
Improving Retrieval Accuracy
Fine-tuning the retrieval component is crucial for improving the accuracy of the retrieved documents. This can involve techniques such as learning better document representations, optimizing the similarity metrics used for retrieval, and incorporating relevant feedback from users or downstream tasks.
One promising approach is to use learning-to-rank methods, which train the retrieval model to optimize ranking metrics such as mean reciprocal rank. By directly optimizing for retrieval quality, these methods can significantly improve the relevance of the retrieved documents.
Enhancing Response Quality
Another challenge in Naive RAG is ensuring the quality and coherence of the generated responses, particularly when integrating information from multiple retrieved documents. Advanced techniques such as content planning and information ordering can help improve the structure and flow of the generated text.
Additionally, methods like information filtering and redundancy removal can help reduce the amount of irrelevant or repetitive information in the final output. By focusing on the most salient and informative content, these techniques can enhance the overall quality and usefulness of the generated responses.
Leveraging External Knowledge Bases
While RAG systems typically rely on a pre-defined knowledge base, a wealth of additional information is often available from external sources such as web searches or structured knowledge bases. Incorporating this external knowledge can help improve the coverage and accuracy of RAG systems. Combining unstructured documents with structured data allows RAG systems to reason more effectively across entities, relationships, and attributes.
Techniques such as entity linking and knowledge graph integration can enable RAG models to leverage these external sources effectively. By connecting the retrieved documents to broader knowledge bases, these approaches can provide additional context and information to enhance the generated responses.
Incorporating User Feedback
Incorporating user feedback is another promising approach for improving the performance of RAG systems over time. By allowing users to provide feedback on the generated responses, such as indicating whether the answer is correct or relevant, the model can learn to refine its retrieval and generation strategies.
This can be particularly valuable in domains where the knowledge base may be incomplete or evolving overtime. By continuously learning from user interactions, RAG systems can adapt and improve their performance based on real-world usage patterns and feedback.
To evaluate the effectiveness of these techniques, researchers often use metrics such as faithfulness metrics, which assess the accuracy and trustworthiness of the generated responses. By measuring the alignment between the generated text and the retrieved documents, these metrics provide a quantitative way to track improvements in RAG performance.
How can Markovate help with RAG Optimization?
Markovate offers a comprehensive suite of tools and services specifically designed to enhance the performance of RAG (Retrieval-Augmented Generation) systems. Our expertise lies in providing advanced solutions that leverage cutting-edge algorithms, data structures, and integration capabilities to optimize RAG workflows.
Our team specializes in implementing advanced RAG methods that align with enterprise requirements, ensuring scalable retrieval, secure data access, and consistently high-quality AI outputs. Here’s how Markovate can help with RAG optimization:
Indexing and Retrieval Capabilities:
We develop algorithms and data structures that form the backbone of indexing and retrieval capabilities. These capabilities enable RAG systems to swiftly and accurately retrieve relevant information from extensive knowledge bases. Whether it’s through keyword-based search, semantic similarity analysis, or hybrid approaches, Our team trains RAG systems to efficiently access the required data. We continuously update and refine the indexing techniques to ensure optimal performance in various scenarios.
Customizable RAG Pipelines:
Markovate provides a flexible framework for building RAG pipelines tailored to specific requirements and preferences. The modular architecture and extensive API allow seamless integration of various retrieval strategies, generation models, and post-processing techniques into RAG workflows. This level of customization ensures that RAG systems can adapt to diverse use cases and domain-specific needs. Markovate offers comprehensive documentation and support to assist companies in building and fine-tuning RAG pipelines according to their unique specifications.
Seamless Integration with LLMs (Large Language Models):
We excel in seamlessly integrating state-of-the-art LLMs, such as GPT-3 and BERT, into RAG systems. By combining the power of pre-trained language models with retrieval capabilities, we can create RAG systems capable of generating high-quality, contextually relevant responses. Markovate simplifies the integration process with straightforward setup procedures for incorporating LLMs into RAG pipelines.
Overall, Markovate serves as a strategic partner for organizations seeking to optimize their RAG systems. Through advanced indexing and retrieval capabilities, customizable pipelines, and seamless integration with LLMs, Markovate builds RAG solutions that excel in delivering accurate, contextually appropriate responses across various domains and applications.
Key Takeaway:
To boost a RAG system’s performance, dive deep into the knowledge base with query expansion and semantic search. Fine-tune retrieval accuracy through learning-to-rank methods and enhance response quality by organizing content smartly. Don’t forget to pull in external knowledge sources for richer responses and use user feedback for continuous improvement.
Conclusion
As we’ve journeyed through the realm of Advanced RAG Techniques today, it’s clear that this isn’t your average tech upgrade. These methods aren’t just another small step forward; they’re completely changing the game in how artificial intelligence digs into and utilizes data to make our lives easier. With the guidance of AI consulting, businesses can harness these techniques to transform operations— from logistics optimizing their supply chains to virtual assistants providing richer interactions, the impact is profound.
As studies continued shedding light on AI’s potential since the early 1960s, it’s evident now more than ever that smart algorithms powered by advanced RAG could very well be among humanity’s most helpful companions.
FAQs
1. How do I evaluate and benchmark the performance of an Advanced RAG system?
Most teams struggle to know whether their RAG system is actually improving. Start by tracking retrieval metrics like MRR, along with answer quality indicators and factual accuracy. Monitor latency and response consistency in real user scenarios. Creating a small internal test set of common business queries helps you benchmark improvements over time.
2. How can I ensure data security, privacy, and compliance in RAG applications?
Organizations often worry about exposing sensitive documents through AI systems. To address this, implement role-based access control (RBAC), encrypt stored embeddings, and filter retrieval based on user permissions. Sensitive fields should be masked before indexing. Audit logs and citation tracking also help maintain compliance in regulated industries like healthcare and finance.
3. Why does my RAG system still hallucinate or give incorrect answers?
This usually happens when retrieved context is weak, outdated, or incomplete. Many teams rely only on vector similarity without reranking or validation. Adding hybrid retrieval, CRAG-style checks, and strict grounding prompts can reduce hallucinations. Regularly updating embeddings also prevents the model from using stale data.
4. What are the most common pitfalls when deploying RAG systems in production?
Teams often face issues like duplicate results, missing table data, broken PDF parsing, or loss of context in multi-turn chats. Another major pitfall is overloading the prompt with irrelevant text. These problems can be reduced with better chunking, parent-child retrieval, context filtering, and continuous pipeline monitoring.
5. How can I optimize RAG systems for better speed and lower operational costs?
High latency and rising cloud costs are common complaints among RAG users. You can improve performance by using approximate nearest neighbor (ANN) indexes, caching frequent queries, and limiting reranker usage. Compressing embeddings and optimizing chunk sizes also helps reduce storage and inference expenses without sacrificing accuracy.
6. How do I implement a reliable RAG pipeline using LangChain and LlamaIndex?
Many developers feel overwhelmed when moving from prototypes to production. A practical approach is to use LlamaIndex for structured ingestion and indexing, LangChain for orchestration, and a vector database for storage. Combine hybrid retrieval, reranking, and CRAG validation before generation. Start with a small pilot system, test it thoroughly, and scale gradually.