Retrieval Augmented Generation (RAG) and Large Language Models (LLMs) like GPT variants both play distinct yet interrelated roles in advancing machine learning applications. Initiated as separate entities—RAG for enhancing data sourcing and LLMs for linguistic processing—their integration culminates in a robust solution for context-aware, domain-specific data generation. RAG introduces a dynamic, real-time data assimilation layer to the static, pre-trained architecture of LLMs. This confluence mitigates the inherent limitations of LLMs, such as computational rigidity and lack of post-training adaptability, by incorporating an external, up-to-date data source. Consequently, the combined RAG-LLM system not only minimizes resource-intensive fine-tuning but also enhances the fidelity and specificity of generated content, effectively countering data distortions commonly referred to as “hallucinations” in linguistic models. To understand this in-depth, we will cover everything about RAG and LLM in this blog.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-augmented generation (RAG) serves as an advanced architectural component for enhancing the output of Large Language Models. It integrates real-time external data repositories, thereby refining the model’s internal data structure. Two core advantages manifest through RAG integration in question-answer platforms based on LLMs. First, it enables the model to tap into a dynamic pool of current and credible facts. Second, it offers the provision for source transparency, granting users the ability to verify the veracity of the model’s assertions. This dual-pronged approach enriches both data accuracy and user trust in automated responses.
How Does Retrieval-Augmented Generation (RAG) Work?
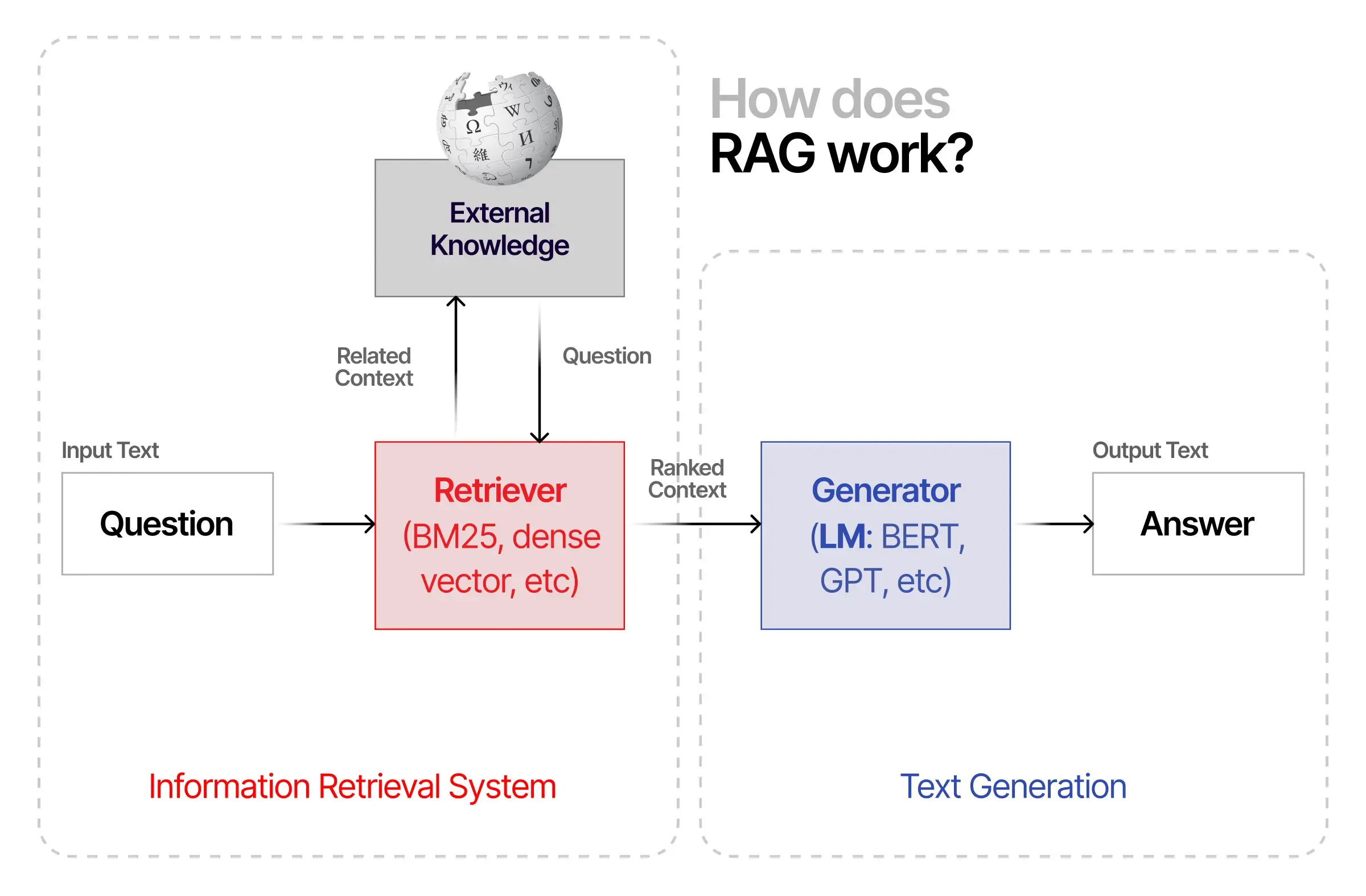
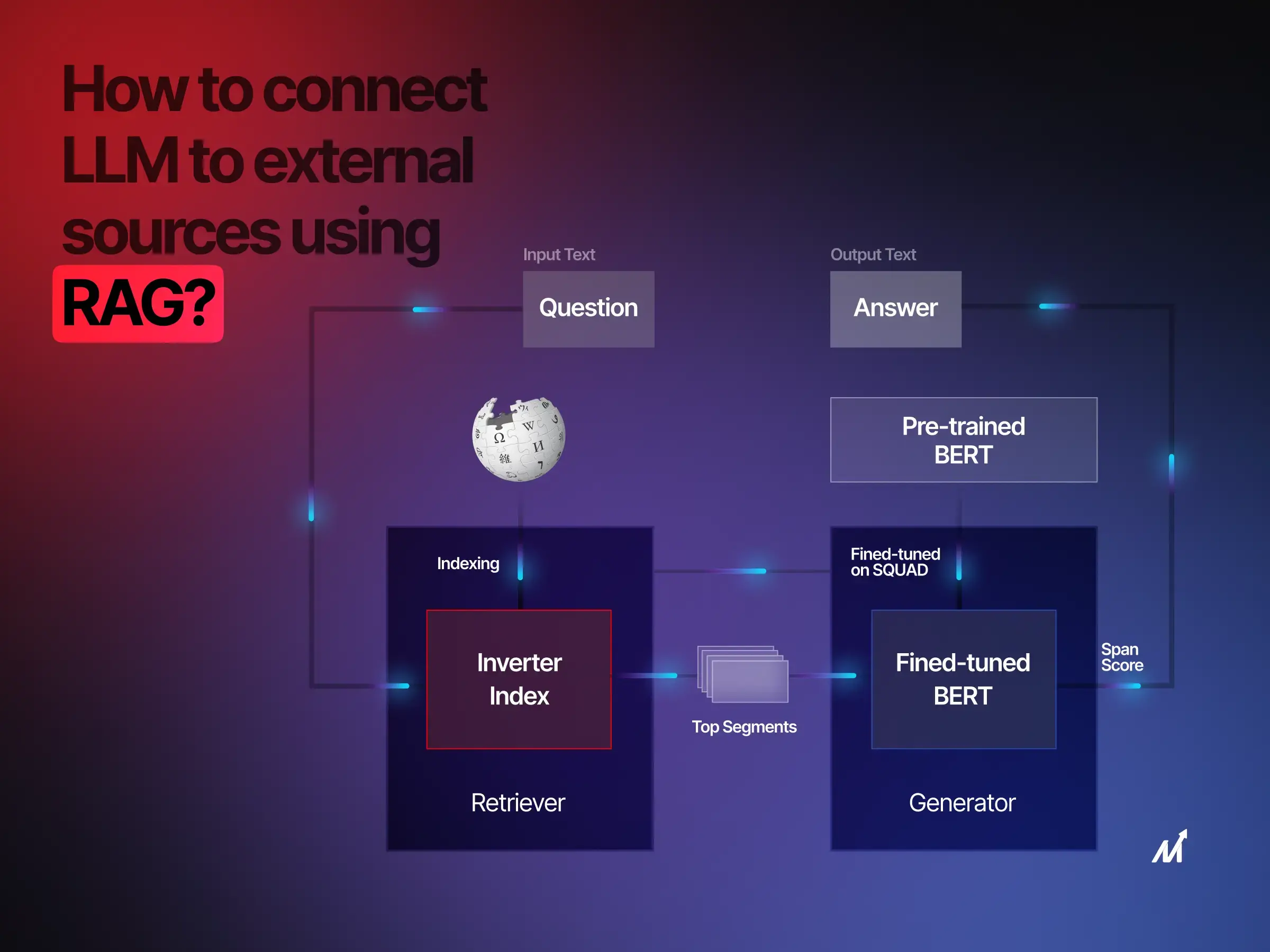
Retrieval Augmented Generation (RAG) equips large language models (LLMs) with the capability to interact with external data sets, both real-time and static, to overcome one of the most frustrating limitations of regular language models, such as ChatGPT—being out of touch with real-time information. This multi-step process can be subdivided into two core phases: Retrieval and Generation.
Phase 1: Retrieval Phase
-
Data Access: Initially, RAG communicates with a plethora of data repositories. This could range from APIs to databases or even domain-specific corpuses. The objective is to glean actionable insights from these expansive data sets.
-
Data Partitioning: Given the voluminous nature of the data, subdividing it into manageable portions is imperative. Each resulting subset functions as an independent entity, enabling easier data manipulation.
-
Vector Transformation: Next, the text contained in each data subset is transmuted into numerical vectors. These numerical sequences encapsulate the semantic nuances of the underlying textual content. This conversion lays the groundwork for machine comprehension of the text’s inherent semantics.
-
Metadata Compilation: Concurrent with the data partitioning and vectorization, metadata is generated. This auxiliary data captures various attributes such as source provenance, contextual cues, and other essential details that aid in data verifiability.
Phase 2: Generation Phase
-
User Input: RAG is triggered by a user-initiated query or statement. This input lays the groundwork for constructing a contextual response.
-
Semantic Interpretation: Similar to the earlier transformation of text to vectors, the user’s query undergoes a parallel transformation. This generates query-specific vectors encapsulating the core intent and meaning behind the input.
-
Relevance Mapping: Leveraging these vectors, RAG performs a targeted search through the pre-existing data subsets. The aim is to pinpoint the subsets that bear the highest relevance to the user’s inquiry.
-
Retrieval-Generation Fusion: Upon isolating the relevant data subsets, their content is amalgamated with the user’s original query.
-
Final Output Composition: This composite data structure—consisting of the user query and relevant data—is then submitted to the foundational language model, potentially GPT. The model then crafts a response that is both contextually apt and informationally rich. This synthesis results in a comprehensive and accurate answer to the initial user query.
Let’s understand one example:
For instance, imagine a customer hits up your chat service and asks about the latest trends in cryptocurrency. A standard language model, isolated from current data streams, would be clueless. This is where RAG comes into the picture. It flips through a constantly updated database, let’s say of financial news, in milliseconds. The system then cherry-picks the most relevant articles and tosses them into the language model. Now, the model has what it needs to craft a well-informed answer.
Since we have covered what RAG is and how it works, let’s understand the core pillars of RAG.
4 Pillars of RAG
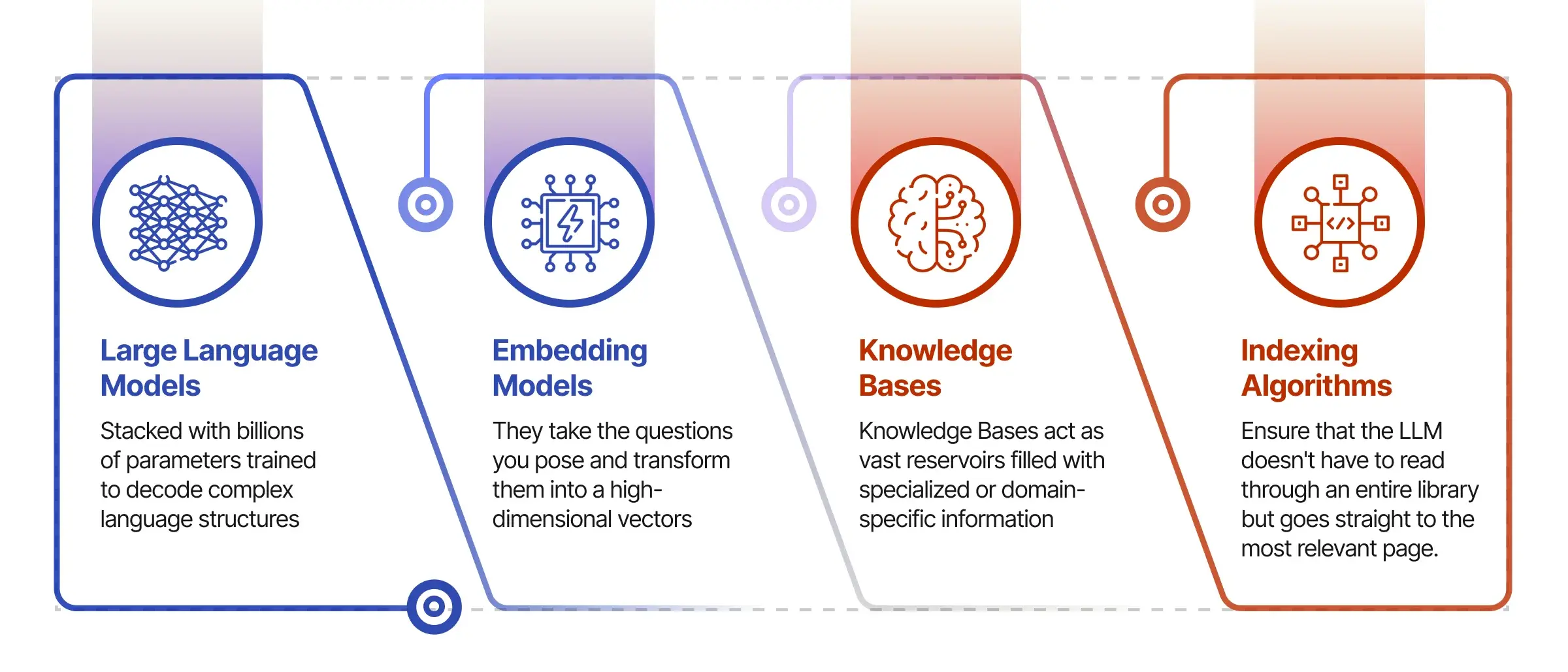
1. Large Language Models: The Intellectual Core
At the heart of any RAG system lies the Large Language Model. It is the intellectual core that interprets language and crafts responses. It’s stacked with billions of parameters trained to decode complex language structures, but it’s not an encyclopedia. It knows the language but lacks specialized expertise. That’s where the other components come into play.
2. Embedding Models: The Bridge to Specialized Knowledge
Embedding models serve as a translation layer. They take the questions you pose and transform them into a mathematical language—high-dimensional vectors, to be exact. This isn’t just fancy math; it’s the crucial step that enables the Large Language Model to tap into specialized external data. These vectors serve as queries that can fetch the information needed to answer your question nuanced.
3. Knowledge Bases: The Treasure Troves of Information
Knowledge Bases act as vast reservoirs filled with specialized or domain-specific information. Be it medical literature, coding repositories, or historical data, these bases are like the external hard drives to your computer, ready to be accessed whenever more detailed information is required. However, the challenge is: How do you sift through such a massive data pool efficiently? By employing advanced indexing and search algorithms, one can overcome this challenge. Techniques such as inverted indices and binary search trees facilitate expedited data retrieval by organizing the information in a manner that significantly reduces search time. Furthermore, utilization of machine learning algorithms like clustering and nearest neighbor search can group similar data together, making the retrieval process even more targeted and efficient. By integrating these advanced algorithms, RAG can sift through voluminous knowledge bases with enhanced precision and speed, ensuring that the most relevant and timely data is accessed.
4. Indexing Algorithms: The Efficient Librarians
Indexing Algorithms aren’t your average search algorithms; they’re designed for speed and pinpoint accuracy. Using methods like Facebook’s AI Similarity Search (FAISS), these algorithms go through Knowledge Bases at lightning speed to retrieve the vectors—essentially the pieces of data—that most closely match your query. They ensure that the Large Language Model doesn’t have to read through an entire library to answer your question but goes straight to the most relevant page.
Advantages of Using RAG
1. Focused and Sharp Answers
The real clincher is how RAG tweaks the quality of responses. Feeding in real-time data ensures the language model’s output is razor-sharp. Forget vague or generalized answers; you now deal with precise, up-to-the-minute information. The retrieval system filters out the fluff, so the language model focuses on what truly matters, improving precision and recall.
2. Contextual Wisdom and Specialized Smarts
Often, businesses struggle with customer queries that are highly specific to an industry or context. RAG levels up the language model’s game by hooking it up to specialized databases or online repositories. This way, even if a customer asks about the nitty-gritty of, let’s say, renewable energy tax credits, RAG provides the language model with the needed specifics, transcending its original training limitations.
3. Speed and Resource Efficiency
Another unsung hero in the RAG system is its knack for streamlining computational muscle. Contrary to the behemoth processing usually needed for large language models, RAG makes do with less. How? By only fetching what’s required. This lean approach slashes latency times, offering quicker yet high-quality responses.
4. Balanced Views, Minimized Bias
The internet is an assortment of opinions, facts, and a fair share of misinformation. RAG is built to select information from a well-rounded set of sources. This minimizes the risk of the language model absorbing and regurgitating biased viewpoints, making the answers both knowledgeable and more balanced and fair.
5. RAG isn’t just an addition
It’s a force multiplier for language models. By imbuing them with real-time accuracy, contextual intelligence, speed, and a balanced worldview, RAG tackles the core challenges that businesses or developers face when deploying language models. It’s like upgrading your regular sedan to a high-performance sports car; only the fuel here is data, and the horsepower is computational brilliance.
Challenges of Retrieval-Augmented Generation (RAG)
1. Knowledge Gap
One of the first hurdles is that companies often don’t fully understand RAG’s inner workings. This isn’t just about learning a new tool; it’s about grasping the complex algorithms and data rules that make RAG work. Given the complexity and specialized knowledge required, it becomes almost indispensable to collaborate with an experienced RAG developer. Such expertise not only bridges the knowledge gap but also ensures the correct, efficient, and optimized implementation of RAG capabilities. For more details on securing a skilled RAG developer, explore our page.
2. Cost and Computing Power
Though RAG is generally more budget-friendly than constant updates to large language models, it comes with its own costs. These can be in the form of computer power needed for real-time data pulling and the merging of this data into the existing model.
3. Data Complexity
The third challenge centers around dealing with different types of data—both orderly and messy. RAG has to sift through this data and know how to use it effectively, which is far from straightforward.
Let’s now understand how to implement RAG to smoothly.
4 Phases of Implementing RAG
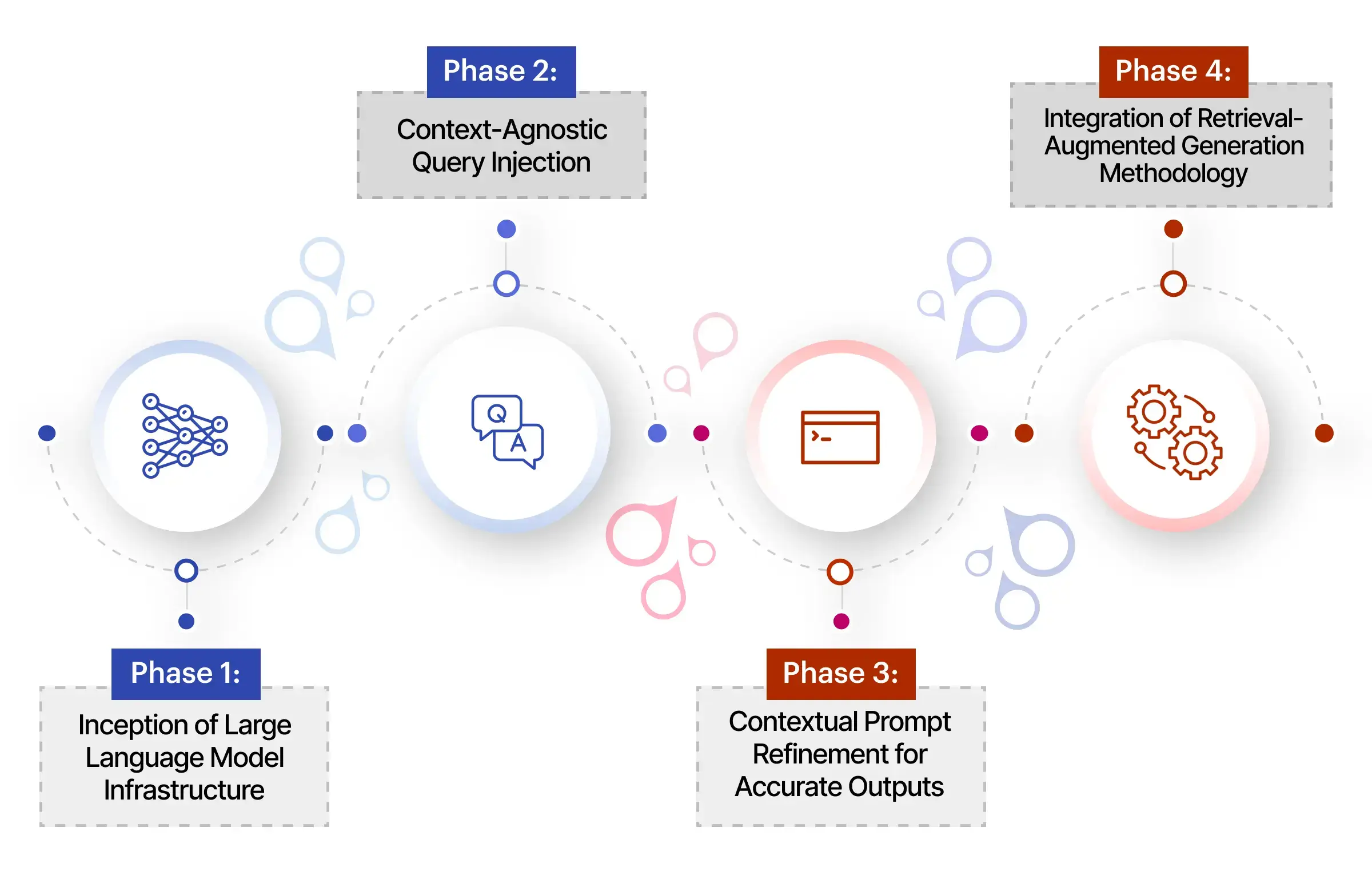
This guide aims to provide a comprehensive walkthrough for integrating Retrieval-Augmented Generation (RAG) with large language models. The goal is to make each phase of the process coherent and connected, allowing for a smooth progression from one step to the next.
Phase 1: Inception of Large Language Model Infrastructure
In the implementation of Retrieval-Augmented Generation (RAG) within Large Language Models (LLMs), the first phase is the integration of a suitable LLM into your existing infrastructure. OpenAI’s GPT series, for example, serves well for text synthesis tasks due to its contextual understanding. However, the output of any LLM is constrained by its training dataset. The inception of this infrastructure is not merely an installation step; it serves as the foundational layer that directly influences the quality and scope of output. Here, the integration is usually accomplished via API calls, and depending on your operational stack, it might necessitate server adjustments for load balancing and latency minimization. These changes aren’t merely operational but strategic, designed to get the most performance and reliability out of your new LLM-RAG infrastructure. Thus, an expert team like Markovate by your side is a must.
Phase 2: Context-Agnostic Query Injection
In Phase 2, the primary objective is to address the limitations of context-agnostic queries by implementing context-aware algorithms that enrich query parameters. Instead of merely directing a simplistic query like “Who was Cleopatra?” to the Language Learning Model (LLM), apply a preprocessing layer that injects relevant contextual data points into the query. This preprocessing could incorporate variables such as time period, geographical relevance, or cultural influence, effectively transforming the query into something more nuanced, like “Cleopatra in the context of Ptolemaic rule and Roman interactions.” By augmenting the query with explicit contextual elements, the LLM’s output will be significantly more precise and informative, thereby overcoming the innate limitations often associated with standalone LLMs.
Phase 3: Contextual Prompt Refinement for Accurate Outputs
This phase functions as the critical juncture where raw user queries undergo a series of computational transformations to output highly precise and contextually aware responses from the Large Language Model (LLM).
1. Syntactic & Semantic Decomposition
Initially, NLP parsers dissect the raw user input into its constituent grammatical and logical elements. Complex algorithms work to isolate subject-verb-object constructs, identify potential modality, and extrapolate any domain-specific terminologies.
2. Prompt Evaluation Metrics
Subsequently, this disassembled input is evaluated using a proprietary set of metrics. These metrics are engineered to quantify critical attributes such as contextual relevance, ontological integrity, and query specificity. The metrics derive scores using machine learning classifiers trained on extensive linguistic databases.
3. Contextual Injection & Refinement
Leveraging the results from the prompt evaluation, a Context Refinement Engine adjusts the original query. It may employ lexical substitution, entity disambiguation, or temporal qualifiers to modify the initial input. This step optimizes the prompt for both linguistic clarity and semantic relevance.
4. Dynamic Context-to-Query Mapping
At this juncture, the RAG (Retrieval Augmented Generation) protocol correlates the optimized prompt with the corresponding vectors in its data retrieval system. Advanced machine learning algorithms work to find the most contextually aligned data vectors.
5. Response Generation
Finally, the modified query vector, along with the associated metadata and selected data vectors, is funneled into the LLM. Specialized algorithms within the LLM then generate a response that has been algorithmically optimized for contextual accuracy and content richness.
The outcome of this phase is a query-specific, highly contextual output from the LLM that aligns with the strategic business or analytical objectives, thereby ensuring actionable insights and superior decision-making capabilities.
Example:
Enhance the reliability and specificity of LLM responses by applying intricate prompt engineering furnished with insightful context. Utilizing a refined query like, “What is Cleopatra VII’s significance in Roman history?” could induce the LLM to generate a response that offers a nuanced depiction of Cleopatra VII’s intricate relationships with key Roman figures like Julius Caesar and Mark Antony.
Phase 4: Integration of RAG Methodology
The application of Retrieval-Augmented Generation (RAG) stands as an imperative to unlock the true potential of Large Language Models. Therefore, this involves a series of meticulous operations, delineated below.
4.1 Deployment of Semantic Embedding Mechanism
The Semantic Embedding Mechanism in this context employs a BERT-based architecture for converting raw text into numerical vectors. These vectors are not arbitrary but semantically rich, capturing the underlying meaning of the document. The mechanism works by leveraging transformer models within the BERT architecture to understand context and semantics. As a result, this transformed representation serves as the foundation for similarity-based document retrieval algorithms, ensuring higher accuracy and relevance in the results..
4.2 Vectorization of Knowledge Repository
Each document housed in the knowledge base should be converted into its corresponding numerical vector representation. This transformation serves as the bedrock upon which document retrieval mechanisms operate. Thus, it is through these vectorized forms that the content’s semantic attributes are captured.
4.3 Indexing of Vectorized Knowledge Assets
Algorithms like the K-Nearest Neighbors (KNN) index the vectorized documents. The indexed vectors serve as searchable entities within the repository, offering rapid access to relevant documents during the query process.
4.4 Retrieval of Topically Relevant Documents
Extract the most semantically aligned documents from the indexed repository by leveraging the query’s vector representation. Consequently, these selections furnish the LLM with contextually pertinent external data, thereby enhancing the quality of the output.
4.5 Composite Query Formulation for LLM
The final operation involves integrating the retrieved documents, refined prompts, and original queries into a single composite input. This integrated input is then processed by the LLM, culminating in generating a highly informed and contextually rich output.
This multi-phase approach constitutes a comprehensive blueprint for harnessing the unadulterated capabilities of Retrieval-Augmented Generation in Large Language Models. Through these meticulous stages, one can achieve unparalleled contextual richness and response accuracy in machine-generated text.
Retrieval-Augmented Generation (RAG) vs. Semantic Search
When it comes to Natural Language Processing (NLP), Retrieval-Augmented Generation (RAG) and Semantic Search represent two distinct but closely related methodologies for information retrieval and contextual understanding. RAG employs a two-fold approach: it initially retrieves pertinent data from a repository and subsequently uses this data to generate contextually coherent and informative responses. This is particularly advantageous for tasks requiring both the extraction and synthesis of complex data.
On the other hand, Semantic Search focuses solely on the retrieval of relevant data based on semantic algorithms that understand the contextual meaning of queries. While it excels in surfacing the most relevant documents or data points, it doesn’t inherently possess the capability to generate new, synthesized text based on that data. Essentially, RAG offers a more comprehensive, context-aware mechanism that can both retrieve and generate information, whereas Semantic Search is specialized in efficient and accurate data retrieval. Both have unique merits, but the choice between the two depends on whether the task at hand requires mere information retrieval or additional content generation.
3 Important Considerations – Connecting LLM to External Sources
When connecting your License Lifecycle Management (LLM) system to external data sources via Resource Allocation Graphs (RAGs), there are three crucial factors to be keenly aware of: Data Privacy, Scalability, and Regular Updates. Addressing each effectively ensures your integrated systems’ secure, robust, and ongoing functionality.
1. Data Privacy
Data privacy isn’t just about compliance, although adhering to laws like GDPR and CCPA is essential. You’ll want to employ strong cryptographic algorithms such as AES-256 for securing data-at-rest and ensure that data-in-transit is equally secure by employing TLS 1.3 protocols. Access controls should go beyond the rudimentary, incorporating both Role-Based Access Control (RBAC) and Attribute-Based Access Control (ABAC). When your LLM communicates with external sources through APIs, use OAuth 2.0 authentication mechanisms and secure tokenization. A Zero Trust Architecture can also bring an additional layer of security, ensuring that each part of the system communicates in isolated, secure environments.
2. Scalability
Scalability is an integral part of future-proofing your RAG and LLM implementation. To adapt to the growing volume and variety of data, containerization techniques such as Docker and orchestration tools like Kubernetes are invaluable. These tools offer dynamic and auto-scalable resource allocation. Employing in-memory data storage like Redis and distributed databases like Cassandra can drastically improve data access times. An event-driven architecture featuring message queues like RabbitMQ ensures your system can manage asynchronous tasks and adapt to changing load conditions without latency.
3. Regular Updates
Finally, regular updates are non-negotiable for maintaining a secure and current system. Implement automation in your update processes with CI/CD pipelines, ensuring you can swiftly adapt to new features and fix bugs. These pipelines should also integrate security scans and vulnerability assessments as part of a DevSecOps approach to keep your system secure. Version control tools like Git can also serve as a safety net, allowing you to roll back updates if they produce unintended effects.
RAG-LLM : Applications & Use Cases
1. Customer Service Automation
Using Retrieval-Augmented Generation (RAG) in a Language Learning Model (LLM) can change the game in customer service. Imagine you’ve got a customer asking complex questions. The system might struggle to find the right answer from its database in a typical setting. But RAG works like a pro here—it quickly pulls the most relevant data, helping the LLM craft a response that’s accurate and context-sensitive. This means quicker and more precise answers, happier customers, and, let’s not forget—lower operational costs.
2. Academic Research
In academic research, time is often of the essence. Researchers need quick access to a sea of publications and data sets. Enter RAG-boosted LLMs. These are not your average search engines; they are designed to understand the intricacies of academic queries. They’ll sift through tons of data in real time and give you back something that’s not just a dump of information but a well-processed, high-quality academic response. It’s like having a super-smart assistant that helps you get to your research conclusions faster.
3. Content Generation
The demand for fresh, tailored material is endless in the content world. Using a RAG-LLM combo can be a game-changer. Say you’re in charge of generating content that needs to be engaging and SEO-friendly. RAG scans through vast data repositories, allowing the LLM to generate original and optimized content for search engines. Unlike older models, where you had to spend time tweaking settings, the adjustments are real-time. The system adapts to new trends, making sure the content stays relevant.
Loved this blog? Read about Parameter-Efficient Fine-Tuning (PEFT) of LLMs: A Practical Guide too.
Future of RAG
Looking at where we are today with RAG technology, it’s clear that we’ve only just scratched the surface. Right now, RAG is doing some pretty cool stuff with chatbots and messaging platforms, making sure that the information you get is timely and spot-on. But think about where this could go in the future. Imagine asking your AI assistant to plan a beach vacation for you, and it doesn’t just find the best spots; it actually takes the initiative to book a cozy cabin near a happening volleyball tournament.
And it’s not just about leisure; this technology could be a game-changer in the workplace too. Forget the days when you had to dig through company manuals to figure out tuition reimbursement policies. With advanced RAG in play, the enterprise environment stands to benefit enormously. Consider a complex, multi-faceted operation like supply chain management. Instead of manually sifting through an array of documents and databases to ascertain the optimal freight routes or inventory levels, an enhanced RAG-driven digital assistant could analyze global trade data, tariffs, weather forecasts, and real-time logistics to recommend the most cost-effective and timely solutions. It could even initiate purchase orders or trigger alerts for inventory replenishment, all while adhering to company policy and budget constraints.
So, when we talk about the future of RAG, we’re really talking about taking AI to a level where it doesn’t just answer your questions—it understands the context, anticipates your needs, and even takes action for you. That’s a future worth looking forward to.
Leveraging Markovate’s Expertise for RAG-LLM Optimization
Through cutting-edge expertise in Enterprise AI, Machine Learning, and Natural Language Processing, Markovate serves as a pivotal technology partner in optimizing Retrieval Augmented Generation (RAG) and Language Learning Models (LLM) integration. Our approach commences with an intricate business requirement analysis to inform tailored algorithm deployment, focusing on intelligent data contextualization rather than mere retrieval. By employing latency-minimized and security-enhanced protocols, we deliver a highly customized RAG-LLM interface that scales effortlessly while maintaining alignment with your strategic objectives. Partnering with Markovate ensures a bespoke technological solution that offers an unparalleled combination of insight, adaptability, and future-proofing.
For further inquiries on how Markovate can facilitate your RAG-LLM optimization journey, don’t hesitate to reach out to our specialized team.
Take the next step: Initiate a consultation with our experts to discuss the full scope and benefits of our RAG-LLM optimization services.
FAQs
1. What is Retrieval-Augmented Generation (RAG)?
Retrieval-augmented generation (RAG) is an advanced machine learning model that synergistically combines the powers of extractive question-answering systems with generative text models. It leverages the query-based retrieval abilities of models like Dense Retriever to pull relevant information from an extensive corpus. The retrieved information is then used by a generative model, often a transformer-based architecture like BERT or GPT, to create contextually accurate and coherent responses. By merging retrieval and generation, RAG accomplishes a dynamic and efficient way of providing high-quality text generation with the added benefit of external information.
2. How Does RAG Work?
The architecture of RAG is quite intricate yet highly effective. First, a query is parsed to the retriever, which searches an indexed dataset for documents that contain pertinent information. The documents are then ranked based on relevance. Subsequently, a contextual token sequence, consisting of the original query and the retrieved documents, is generated and passed on to the generative model. This model then utilizes its internalized language understanding and context-aware algorithms to output a well-formed, highly relevant response. In this fashion, RAG provides the best of both worlds—retrieval and generation—in one unified model.
3. How Can You Connect Your LLM to External Sources Using RAG?
LLMs can greatly benefit from the external information-sourcing capabilities of RAG. Your LLM can dynamically pull data or information from external datasets, APIs, or databases by incorporating RAG. This expands the LLM’s knowledge base beyond its pre-trained parameters, thus allowing for more informed and nuanced responses. Connecting an LLM to RAG generally involves API calls to initiate the retriever and the subsequent generation steps. The system must also handle tokenization and decoding processes to ensure seamless data flow between the LLM and RAG components.
4. What Are the Technical Benefits of Using RAG?
Integrating RAG into your LLM offers several technical advantages:
1. It significantly expands the scope and quality of responses, as the model can tap into extensive external datasets for additional context and validation.
2. The hybrid architecture optimizes computational resources; the retriever’s indexing reduces the data the generative model needs to process.
3. The modular design of RAG makes it highly customizable.
You can swap out the retriever or generative components to better fit specific domain requirements, thus providing a scalable and versatile solution for various complex text generation tasks.
5. What is the relationship between RAG and LLM?
Retrieval-Augmented Generation enhances the capabilities of Large Language Models (LLMs) by connecting them to external or internal data sources without requiring model retraining. This allows LLMs to access up-to-date, domain-specific, or organization-specific information in real time. RAG ensures the generated responses are more relevant, accurate, and context-aware, making it a cost-effective way to tailor LLM output for specific business or knowledge use cases.
6. How do you choose the right LLM for RAG?
Selecting the right LLM for RAG depends on several key factors: the model’s context length (how much information it can handle at once), its performance in generating accurate and coherent outputs, cost-efficiency based on usage, and how well it fits your domain-specific needs. It’s important to align the model’s capabilities with the complexity and scale of your use case to ensure optimal results.