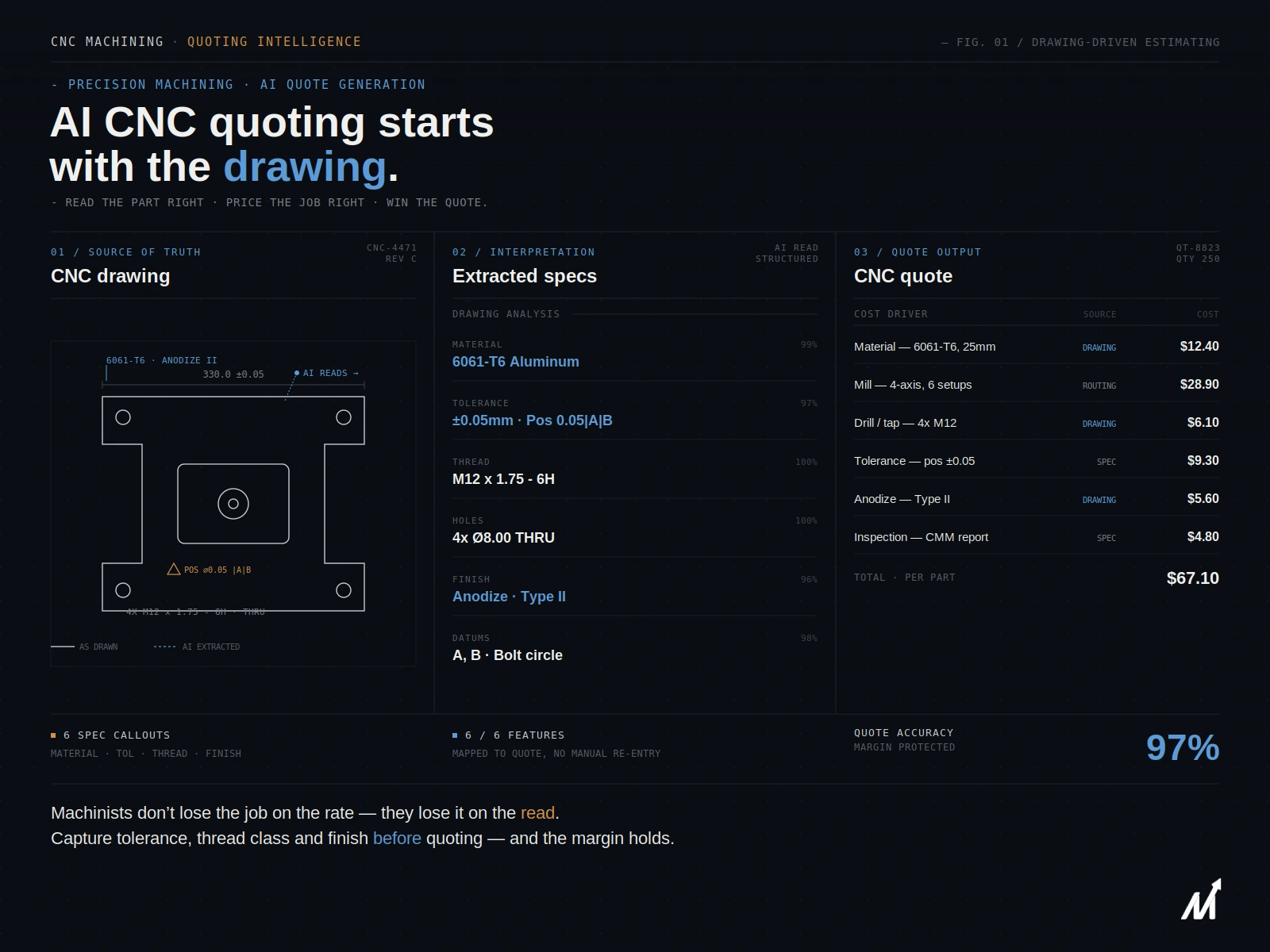
Imagine walking into a modern office space. Without even thinking, your eyes scan the room. You notice the layout, where people are seated, who’s engaged in a conversation, and so much more. All this happens within a blink of an eye, thanks to the complexity of human vision that’s been honed by evolution and everyday experiences.
Now, think about bringing this level of perception to a business operation. The kind where computers could actually “see” and “understand” what’s going on around them. That’s the game-changing power computer vision brings to the table. Forget the old days when computers could only recognize rudimentary shapes or patterns; we’re talking about machines that can identify objects, read expressions, and even interpret actions.
This isn’t some sci-fi fantasy anymore. With the surge in machine learning capabilities and raw computational power, computer vision has burst onto the business scene as a must-have tool for a whole range of applications—from automating quality checks in manufacturing lines to enhancing customer experiences in retail spaces.
And this is not some fly-by-night trend. The financials back it up. Industry projections peg the value of the computer vision market at a staggering $41.11 billion by 2030. That’s riding on a solid Compound Annual Growth Rate (CAGR) of 16.0% from 2020 to 2030. So whether it’s optimizing workflows or unlocking new avenues for customer engagement, computer vision is poised to redefine how businesses operate and succeed in the coming decade. Let’s dive deep and understand more about computer vision applications and its architecture.
What is Computer Vision?
Computer vision is an area of artificial intelligence that helps machines ‘see’ and understand visual information from the world—much like human eyes and brains do. In the past, computers could only identify simple shapes or text. But thanks to deep learning and neural network advancements, computer vision has improved drastically.
The goal is simple: teach machines to process images or videos and make decisions based on that data. For example, a computer vision system can look at a traffic camera feed and decide whether there’s a traffic jam.
5 Pillars of Computer Vision
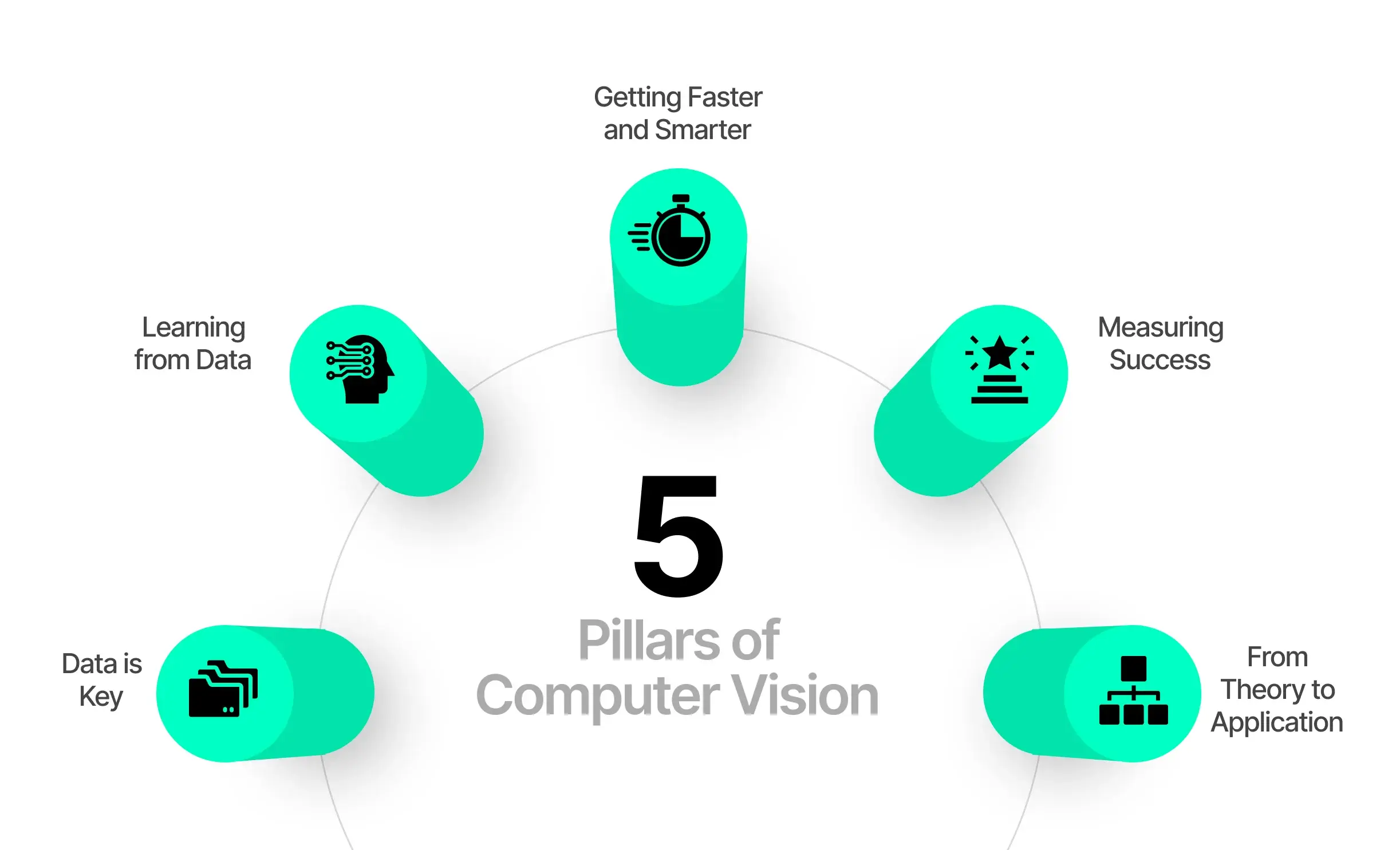
- Data is Key: The more images a computer sees, the better it gets at recognizing patterns. People upload billions of photos every day on the internet. This massive volume of images helps train computers to improve their tasks.
- Learning from Data: Computers use complex algorithms, like Convolutional Neural Networks (CNNs), to scan through these images and learn from them. Think of CNNs as digital detectives. They look for clues like edges, textures, and colors to understand what’s in an image.
- Getting Faster and Smarter: Better hardware, like Graphics Processing Units (GPUs), allows computers to analyze images much faster. This speed is essential for real-world applications like self-driving cars that must make split-second decisions.
- Measuring Success: Knowing how well a computer vision system is performing is important. Modern systems use metrics beyond just accuracy. They also measure how precise the design is or how often it gets a specific type of object correct, among other things.
- From Theory to Application: What started in the 1950s as basic experiments have now found real-world applications. Today, computer vision is used in healthcare for medical imaging, autonomous vehicles for navigation, and retail to analyze consumer behavior.
So, computer vision has come a long way. It now has the power and data to outperform humans in specific visual tasks. Expect more advancements as computers get even faster and data continues to grow.
Decoding the Inner Workings of Computer Vision Applications/ Systems
In Neuroscience and Machine Learning, one of the greatest puzzles is understanding the computational mechanics of the brain. Although Neural Networks claim to simulate these mechanics, no definitive theory validates such a claim. This complexity spills over into computer vision, which lacks a standard yardstick to compare its algorithms to the human brain’s image-processing abilities.
At its core, computer vision is about recognizing patterns in visual data. One would typically input a large dataset of labeled images to train a system in this domain. These images are then processed through various specialized algorithms that can identify multiple attributes like color patterns, shapes, and the spatial relationships between these shapes.
To illustrate, consider training a system with images of cats. The algorithm sorts through each image, identifying key features such as colors, shapes, and how these shapes relate to each other in space. This analysis allows the computer to build a composite “cat profile,” which it can then use to identify cats in new, unlabeled images.
Now, diving into some technical specifics, think about how a grayscale image, like a portrait of Abraham Lincoln, is processed. In this format, each pixel’s brightness is coded into an 8-bit number, ranging from 0 (black) to 255 (white). The computer can effectively interpret and analyze the image by converting the visual elements into numerical data. It proves that computer vision systems can extend their capabilities beyond simple pattern recognition into more complex yet highly effective visual data interpretation mechanisms.

Computational Speed in Image Interpretation: A Quantum Leap
Advancements in computational capabilities have exponentially accelerated the speed at which image interpretation occurs. Gone are the days when supercomputers would require extended periods to perform exhaustive calculations. Modern hardware architectures, high-speed internet connectivity, and cloud infrastructure have synergized to make data interpretation nearly instantaneous. Notably, giants in the AI research domain like Google, IBM, and Microsoft have accelerated this progress by contributing to open-source machine learning initiatives.
The net result is an AI landscape that has become exceptionally agile, wherein experimental workloads that formerly required weeks can now be executed in minutes. For applied computer vision cases, latency has been reduced to microseconds, achieving what is known in computational science as “contextual awareness.”
Understanding Computer Vision Applications
Computer Vision is focused on enabling machines to interpret and make decisions based on visual data—has become a cornerstone for innovation across various sectors. From healthcare to retail, computer vision applications are radically transforming traditional business models, driving efficiency, enhancing customer experiences, and unlocking new revenue streams. Having understood this groundwork, let’s delve into some of the most techniques employed, from basic algorithms to sophisticated machine learning architectures. Take note of the following notable deployments:
-
Algorithms for facial identification within mobile photography suites that automate content curation and enable precise tagging in digital social environments.
-
Algorithms for detecting road demarcations integrated into autonomous vehicles operating at high velocities ensure safe and accurate navigation.
-
Engines for optical text recognition that empower applications designed for visual queries to interpret text patterns within captured images.
While these computer vision applications manifest diverse functionalities, they are all anchored by a fundamental similarity: they leverage unprocessed and often disordered visual inputs to produce structured, understandable data. This transformation enhances the value delivered to the end-user by converting what would otherwise be ambiguous visual information into actionable intelligence across multiple application domains.
The Intricacies of Video Data Manipulation: Operational Quandaries for Engineers
Perception of video content varies significantly between a consumer and an engineer. To the former, a video presents as a singular, fluid entity, while for the latter, it unfolds as an ordered sequence of individual frames. This distinction becomes pivotal when engineering tasks such as real-time vehicular motion analytics require execution. The preliminary steps involve the extraction of singular frames from the raw video data, followed by applying specialized algorithms for vehicle identification and tracking.
The sheer volumetric demands of raw video data pose a logistical challenge. To quantify a single minute of raw footage, capturing 60 frames per second (fps) with a resolution of 1920×1080 pixels requires storage capacities exceeding 22 gigabytes.
The mathematical representation would be:
60 sec×1080 px (height)×1920 px (width)×3 bytes per pixel×60 fps=22.39 GB60 sec×1080 px (height)×1920 px (width)×3 bytes per pixel×60 fps=22.39 GB
Given these constraints, raw video data is untenable for real-time processing or effective storage. The data must undergo a compression process to become manageable. Yet, herein lies another layer of complexity. The compression parameters, determined at the operation’s time, dictate individual frames’ fidelity. A compressed video may offer satisfactory playback quality, but that doesn’t necessarily correlate with the integrity of its constituent frames for analytical purposes.
Recognizing these challenges, this analysis delves into practical strategies involving renowned open-source computer vision utilities to tackle rudimentary video data processing challenges. These insights equip engineers with the understanding to tailor a computer vision workflow in alignment with specific application requisites. It’s imperative to clarify that the scope of this discourse deliberately omits the auditory dimensions of video data.
Engineers commonly leverage frameworks like OpenCV or TensorFlow to dissect video files into individual frames. These tools allow for the extraction and temporary storage of frames for further processing. It’s important to note that while compression is almost inevitable for video storage, special attention must be paid to the choice of codec and compression ratios when the video is intended for analytical processes. Algorithms such as H.264 or VP9 may offer good compression ratios. Still, their lossy nature could be detrimental when a high level of detail is essential for tasks like object detection or activity recognition.
Computer Vision Applications Example Tutorial
Creating an Advanced Computer Vision Framework for Luminance Assessment:
1. Architectural Framework
To establish a sophisticated computer vision pipeline, a team of engineers collaboratively builds a series of modules to handle complex tasks. The fundamental elements of this architecture integrate seamlessly to calculate the luminance across discrete frames of a video.
This conceptual framework is implemented as part of SpectraVision, an advanced library engineered in Rust, which supports functionalities beyond computer vision pipelines. SpectraVision incorporates TensorFlow bindings for object identification Tesseract OCR for text extraction, and facilitates GPU-accelerated decoding for enhanced performance. To use, clone the SpectraVision repository and execute the command cargo add spectravision.
2. Technology Suite Employed
FFmpeg: Universally acknowledged for its video manipulation capabilities, FFmpeg is a C-written, open-source library. It is the backbone for video decoding, employed in enterprise-grade applications like VLC Media Player and OBS.
Rust: Notable for its capacity to detect memory-related errors during compile time, Rust is employed for its efficiency and performance, making it ideal for video analysis.
Procedural Steps
Step 1: Video Ingestion
A previously acquired sample animation video undergoes initial processing here.
Step 2: Preliminary Video Conditioning
Convert the H.264 encoded video to raw RGB format using FFmpeg. Execute FFmpeg commands within the Rust environment, using appropriate arguments to decompress and convert the video sample to raw RGB.

Step 3: Buffer Management
With the video decoded into raw RGB, SpectraVision utilizes a dynamic buffer to manage large data sets. Memory is efficiently recycled after each frame has been processed.

Step 4: Luminance Quantification
To gauge the average luminance of each preprocessed frame, implement the following function within the Rust code.

Step 5: Analytic Output
Luminance values are systematically assessed, and the resulting data signifies the degree of brightness fluctuations across individual frames. This analytical data offers a substrate for numerous applications, including video quality optimization and machine learning model training.
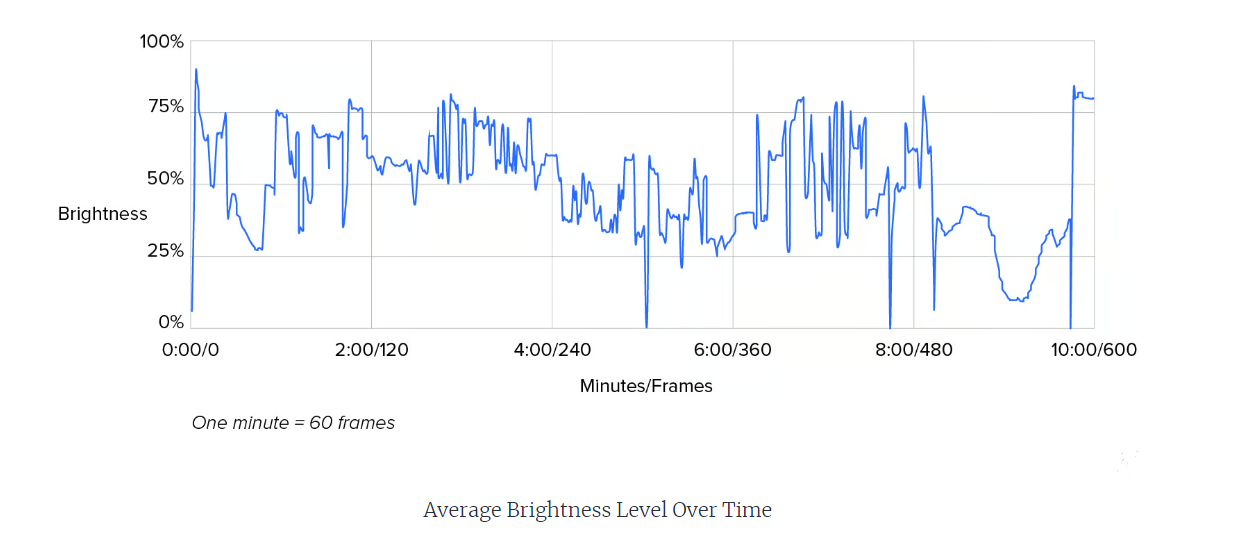
The graphical representation encapsulates the luminance fluctuations across the video timeline. Distinct peaks and troughs demonstrate abrupt changes in frame brightness. Such acute shifts signify standard cinematic transitions, and the analytical data can be further utilized for optimizing video stream quality or machine learning model training.
Applications of Computer Vision: An Analysis
1. Autonomous Vehicles and Computer Vision
For autonomous vehicles, computer vision acts as the cornerstone for situational interpretation. A series of high-definition cameras offer multi-angle views that complex algorithms ingest in real-time. The computational framework identifies road margins, deciphers traffic signs, and pinpoints other entities like vehicles, objects, and pedestrians. The autonomous system processes this data, enabling the vehicle to navigate complex traffic conditions and terrains, optimizing safety and efficiency.
2. Facial Identification Through Computer Vision
Computer vision significantly contributes to facial identification technologies, optimizing security and functionality across devices and applications. Specific algorithms scrutinize facial features within an image and cross-reference them with extensive facial profile databases. For example, consumer electronics employ these techniques for secure user authentication, while social media platforms implement them for user identification and tagging. Additionally, law enforcement applications utilize advanced versions of these algorithms to identify suspects or persons of interest from multiple video feeds.
3. Augmented and Mixed Realities: Computer Vision’s Role
Computer vision is pivotal in augmented and mixed reality technologies, particularly in identifying object placement within a real-world context. These algorithms detect real-world planes, such as walls and floors, crucial for establishing depth and dimensionality. This data is then used to accurately overlay virtual elements onto the physical world as seen through devices like smartphones, tablets, or smart glasses.
4. Healthcare: A New Frontier for Computer Vision
In healthcare technology, computer vision algorithms offer significant promise for automating diagnostic procedures. For instance, machine-assisted interpretation can effectively detect malignant growths in dermatological images or identify anomalies within X-ray and MRI scans. Such automation augments diagnostic accuracy and substantially reduces the time and labor involved in medical analysis.
This multi-vertical application of computer vision, underpinned by cutting-edge computational capabilities, represents a technological evolution and a paradigm shift. The potential is vast, and the practical implementations we witness today may just be the tip of the iceberg.
Top Computer Vision Algorithms
Dissecting Advanced Algorithms in Computer Vision: A Comprehensive Examination
1. SIFT: Scale-Invariant Feature Transform Algorithm
Introduced in 2004, the Scale-Invariant Feature Transform (SIFT) has become instrumental in extracting local features within digital imagery for object detection and recognition tasks. The algorithm employs a four-step process to achieve its objectives.
- Scale-Space Extrema Detection: This initiates the hunt for potential key points by leveraging a difference-of-Gaussian (DoG) function across various image locations and scales.
- Keypoint Localization: After extrema detection, a fitting model gauges keypoint location and scale based on stability parameters.
- Orientation Assignment: Gradients of local image regions guide the orientation assignment for each key point. This step ensures transformation invariance in subsequent operations.
- Keypoint Descriptor: Quantitative gradients from local image regions around each keypoint transform into a descriptor representation resilient to local distortion and varying illumination.
Practical Utility of SIFT
Applications are wide-ranging, from object recognition in 2D to 3D reconstructions, motion tracking to panorama stitching, and robotic navigation to individual animal recognition.
2. SURF: Speeded-Up Robust Features Algorithm
SURF, an efficient approximation of SIFT, accelerates feature detection while retaining robustness against image transformations. Composed of a two-step process, SURF makes use of a Hessian matrix approximation for feature extraction and description.
- Feature Extraction: Relies on a Hessian matrix approximation to zero in on an image’s interest points.
- Feature Description: After fixing an orientation based on the circular region surrounding the key point, a square region aligned with this orientation is chosen for descriptor extraction.
Practical Utility of SURF
Among its uses are object recognition, 3D reconstructions, and image classification. It optimizes contrast-based feature matching, thus enhancing the speed of such operations.
3. Viola-Jones Object Detection Framework
Developed primarily for face detection, the Viola-Jones framework employs Haar-like features to identify faces in images. The algorithm comprises four main phases:
- Haar-Like Feature Selection: Select sub-regions within the image to identify potential object-specific features.
- Integral Image Calculation: Facilitation of rapid computation of feature values.
- AdaBoost Training: Utilization of machine learning techniques for effective feature selection.
- Cascade Classification: Sequential classifiers are deployed to speed up detection, minimizing false positives.
Practical Utility of Viola-Jones
Though initially engineered for face detection, its use cases have expanded to object tracking, real-time attendance systems, and much more. It established foundational methods in real-time object detection.
4. Kalman Filter: The Time-Domain Filter for Object Tracking
One of the pioneering techniques in obstacle detection, the Kalman Filter, has far-reaching applications in tracking and predicting object positions.
- Initial Estimation: Utilizes historical data to generate an initial object position.
- Prediction: Employs the prior estimates and process models to forecast future positions.
- Estimation Update: Compares the prediction with observational data, refines the estimation, and updates model parameters for future predictions.
Practical Utility of Kalman Filter
The Kalman Filter’s applicability transcends beyond computer vision into robotics, aerospace, and maritime navigation. Originally developed for NASA’s Apollo program, it is extensively utilized in robotics for autonomous navigation and various tracking and detection systems.
Loved this? Read about building AI System too.
Build Computer Vision Applications with Markovate
Understanding computer vision isn’t just about code and algorithms; it’s about creating a system that sees and understands the world as we do. That’s where Markovate comes in. We’ve got the tech stack know-how to build you a computer vision pipeline that’s as robust and efficient. From getting your hands on the right data to deploying models that make sense, we’ve got you covered.
Here’s how it works: First, we ensure you’re collecting high-quality data for your specific needs. Then, we clean it up and prepare it for the heavy lifting. Our team dives deep into feature extraction, ensuring the most important details are ready and available for the machine-learning models that follow. Once everything’s set, we bring in our top-of-the-line models, trained on vast and varied datasets, to turn that data into actionable insights.
But what sets us apart is our focus on your business goals. Whether you’re looking to automate quality checks in a factory setting or step up your security game with real-time analytics, we’re here to make it happen. With Markovate’s expertise in generative AI development services, you’re not just getting a technological solution but investing strategically in your organization’s future.
So, are you ready to take your computer vision projects to the next level? Contact Markovate today, and let’s build something amazing together.
FAQs
1. What Constitutes a Basic Computer Vision Pipeline Architecture?
A standard pipeline starts with data acquisition, where we collect images or video frames. Preprocessing steps like noise reduction and normalization follow this. Feature extraction comes next, identifying elements like edges or textures. Finally, the decision-making process may involve machine learning algorithms to interpret these features and make actionable insights.
2. How Important is Preprocessing in the Pipeline?
Preprocessing is not just a preparatory step; it’s often pivotal for the entire system’s performance. Poorly preprocessed images can lead to inefficiencies and inaccuracies in feature extraction and eventually impact decision-making. Therefore, noise reduction, color transformations, and image resizing are essential for system robustness.
3. Can the Architecture Be Modified for Specific Applications?
Absolutely. The architecture features modularity and can tailor to meet the needs of applications. Take example of medical imaging, incorporating additional steps for anomaly detection make sense. The optimization of feature extraction can help in for real-time processing in autonomous vehicles.