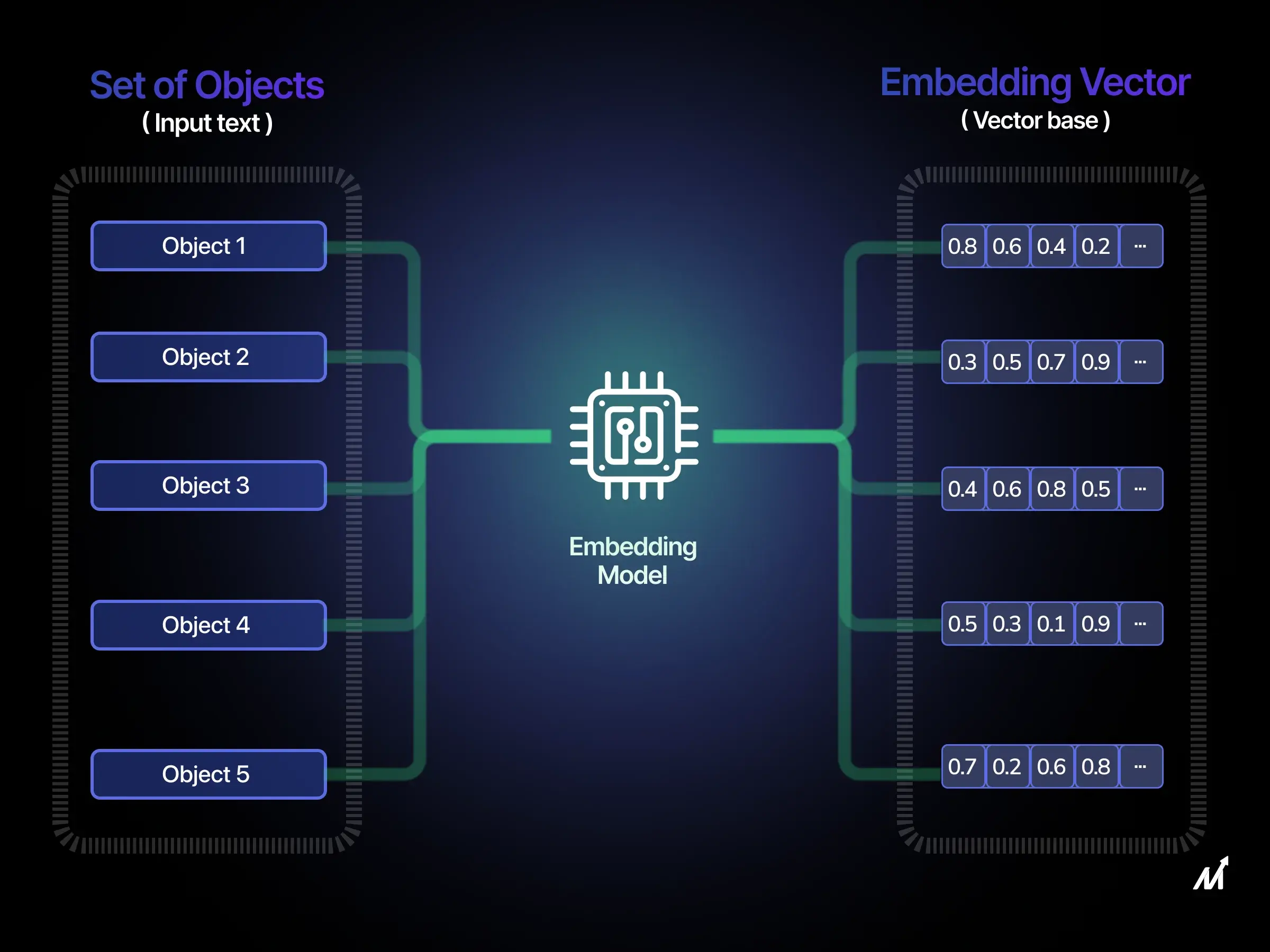
What is Embedding?
Embeddings turn complex data like text or images into simpler, numerical forms. Think of it like turning a whole book into a summary that still captures the book’s main points. This makes it easier to work with large sets of data. The key idea is to keep the important relationships between data points, even in this simplified form.
For example, if you have a question like, “What is the importance of democratic participation?” that question can be turned into a number form (a vector) using embeddings. This number form can then be used in calculations to compare it to other questions or statements to see how similar or different they are in meaning.
This isn’t just for text; the same idea applies to images. We can turn an image into a numerical form that captures its main features. This makes it easy to compare the image to other types of data, like text.
Embeddings are especially useful in recommendation systems, like the ones that suggest what movie to watch next on a streaming service. They help make these systems faster and more accurate by simplifying the data but keeping its key characteristics. This leads to better recommendations for users. Let’s dig deep into Embeddings and learn about it’s types, significance, top models, etc. in this blog.
Deciphering the Types of Embeddings: Text Vs. Image
Embedding generation within deep learning architectures offers an array of methodologies, each bearing unique capabilities and limitations. The selection of an embedding strategy is contingent on the desired application and the nature of the data input. These strategies may employ recurrent neural networks (RNNs), convolutional neural networks (CNNs), or alternative paradigms, all aimed at synthesizing high-fidelity embeddings that encapsulate the latent semantic content of the data.
1. Text Embeddings: The Backbone of NLP
The transformation of textual data into numerical vectors, termed “textual embeddings,” constructs a mathematical framework for text manipulation. Often conflated with text encoding, which transmutes raw text into tokenized forms, textual embeddings offer a more intricate representation. Within a sentiment analysis workflow, textual embeddings and text-encoded feature sets are integrated. Utmost diligence must be exercised to harmonize the language models applied in textual embedding and text encoding stages. Prevalent models such as the Neural Network Language Model (NNLM), Global Vectors (GloVe), Embeddings from Language Models (ELMo), and Word2Vec specialize in generating these word-level vectors endowed with semantic richness.
2. Image Embeddings: Pioneering Computer Vision
When it comes to images, visual embeddings facilitate the condensation of pictorial data into numerical vectors, encapsulating the essential features and properties of the image. Deep learning algorithms act as catalysts in this conversion process, gleaning features that are, after that, encapsulated in a vectorial form. This vectorial manifestation finds utility in diverse operations including image retrieval, object identification, and image taxonomy
Distinctive methodologies for visual embedding exist, each optimized for specialized functions. Certain techniques necessitate off-site processing, requiring the image data to be sent to a remote computational hub. Conversely, some methodologies, like the SqueezeNet embedding algorithm, function effectively in a local computational environment, negating the need for internet connectivity and facilitating swift image analyses.
|
Feature |
Text Embeddings |
Image Embeddings |
|
Data Type |
Textual data (words, sentences, paragraphs) |
Visual data (images, frames of a video) |
|
Dimensionality |
Typically lower-dimensional (e.g., 50-300 dimensions) |
Usually higher-dimensional (e.g., hundreds to thousands of dimensions) |
|
Underlying Models |
Word2Vec, GloVe, FastText, BERT, GPT |
CNNs, AutoEncoders, GANs, ResNet, VGG |
|
Objective |
To capture semantic and syntactic relationships between textual entities |
To capture visual features like edges, textures, colors, and patterns |
|
Use Cases |
Natural Language Processing, sentiment analysis, machine translation |
Image recognition, object detection, image-to-image translation |
|
Similarity Metrics |
Cosine Similarity, Euclidean Distance |
Cosine Similarity, Euclidean Distance, Mahalanobis Distance |
|
Training Data |
Text corpora (Wikipedia, news articles, etc.) |
Image databases (ImageNet, CIFAR, etc.) |
|
Computational Complexity |
Generally lower compared to image embeddings |
Generally higher due to the complexity of image data |
|
Preprocessing |
Tokenization, stemming, lemmatization |
Resizing, normalization, augmentation |
The Significance of Embeddings in Transformer Models
Vector embeddings are instrumental in elevating the efficacy of transformer architectures, a vital backbone in NLP platforms like ChatGPT. Unlike conventional machine learning architectures that utilize fixed and unchangeable weight matrices, transformers leverage mutable weight configurations—akin to the flexibility afforded by dynamically typed programming languages via their REPL environments. These ML embeddings manifest as a condensed dimensional layer, offering a harmonious structure to voluminous high-dimensional arrays, thereby augmenting a model’s prowess in human language understanding and classification tasks.
Within data shape or ‘dimensionality,’ embeddings are a pivotal mechanism. They engender a compact dimensional realm where extensive high-dimensional vectors can be accurately represented. In layman’s terms, embeddings are a linchpin in amplifying the performance of mutable weight frameworks like transformers, thereby establishing them as formidable tools for natural language comprehension and other data-driven operations.
Key Facets of Embeddings’ Significance
-
Semantic Coherence: The ML embeddings encapsulate semantic correlations in input variables, facilitating straightforward comparative analysis. Their integration ameliorates various NLP objectives, ranging from sentiment delineation to textual categorization.
-
Computationally Efficient Dimensionality: By generating a lower-dimensional continuum, embeddings make it feasible to manipulate expansive data inputs while curtailing computational intricacies inherent in intricate machine learning algorithms.
-
Versatility Across Models: Post-creation, an embedding set becomes a reusable asset. It can be transposed across diverse models and operational frameworks, thus constituting an efficient, multipurpose toolset for data scrutinization.
-
Resiliency and Scalability: Due to their capacity for training on voluminous data sets, embeddings are adept at grasping latent structural associations within the data. This attribute endows them with a robustness that is compatible with a multitude of industrial applications.
Top Embedding Models You Should Know
Navigating through the landscape of embedding models is essential for understanding complex data relationships. Let’s delve into the top models that are shaping the future of machine learning and AI, uncovering the functionalities that make them indispensable for data scientists today.
1. Principal Component Analysis (PCA): Simplifying Complexity
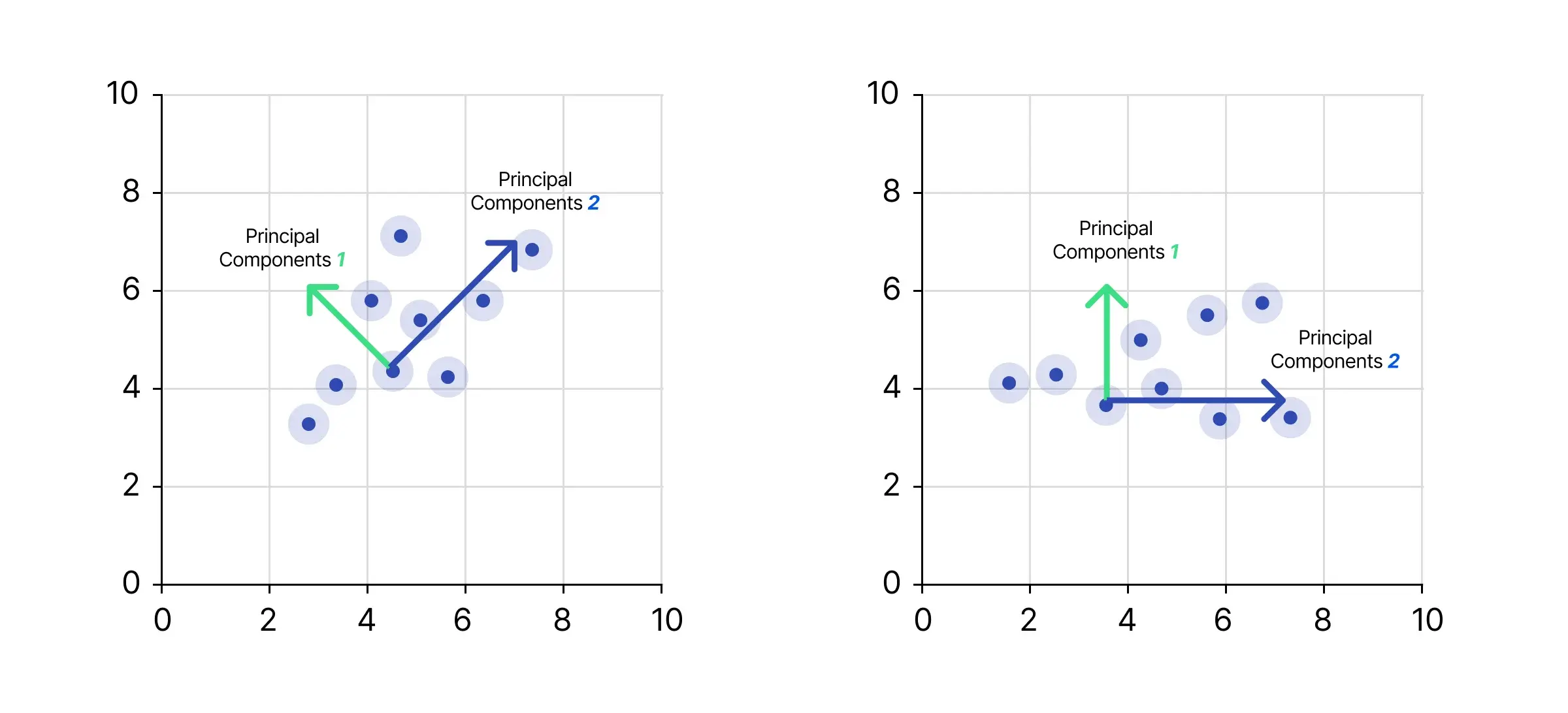
A dominant fixture in machine learning and data manipulation, Principal Component Analysis serves as a high-potency method for dimensionality curtailment. The modus operandi involves the computation of linearly independent variables, termed ‘principal components.’ These components encapsulate the data variance crux, presenting a compressed yet highly informative variant of the initial data set. Thus, they lend themselves as effective attributes for training machine learning models. PCA elucidates patterns in multidimensional data landscapes, showing prowess in various domains ranging from textual analytics to visual data exploration and feature distillation.
2. Singular Value Decomposition (SVD): The Silent Performer in Data Reduction
Singular Value Decomposition, or SVD, is ubiquitously employed across multiple sectors, from machine learning paradigms to intricate data analytics. At its core, SVD performs matrix disintegration, breaking a given matrix into two truncated matrices that facilitate dimensional truncation. In consumer-behavior matrices, such as rating grids for media or consumer goods, SVD creates two sub-matrices—item embeddings and user embeddings. These computational artifacts efficiently capture inter-relational data between items and consumers. Thus, the dot product of an item’s and a user’s embeddings is a reliable predictor for user preferences, enabling sophisticated recommendation algorithms.
3. Word2Vec: The Gold Standard in Text Embedding
Word2Vec remains an instrumental algorithm for word embedding creation in natural language processing. It assesses co-occurrence patterns within a textual corpus to formulate highly indicative vectors, also known as embeddings. These vectors offer valuable insights into semantic and syntactic relationships, transcending mere frequency analysis. For instance, words such as ‘king’ and ‘queen’ would manifest proximal embeddings owing to their common contextual appearance. This facilitates the machine’s capacity to generate meaningful word analogies, enhancing its grasp over complex language structures.
4. BERT (Bidirectional Encoder Representations of Transformers): The New-Age Marvel of Embedding
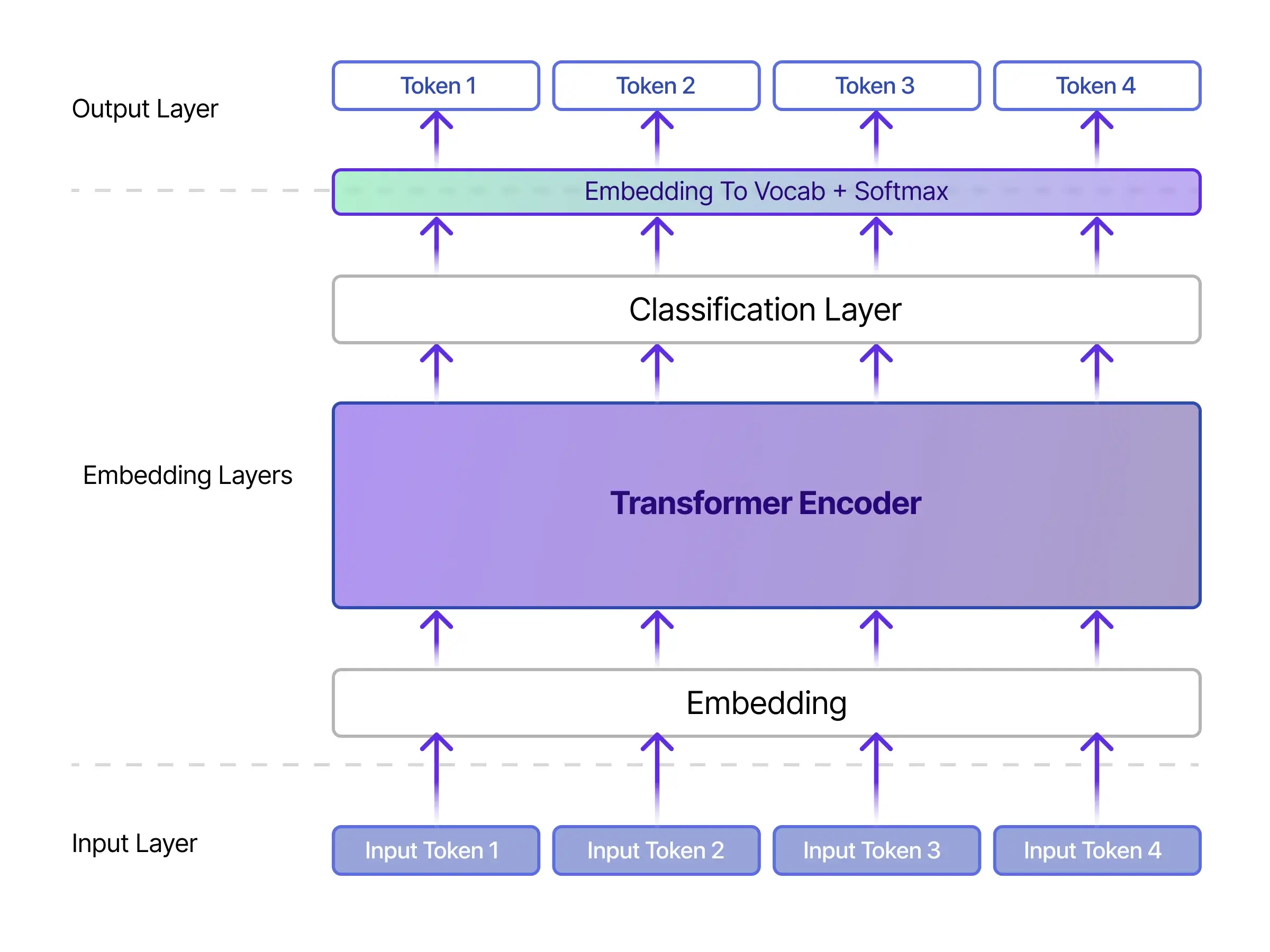
Touted as a paradigm shift in natural language understanding, BERT operates through an advanced two-phase learning regimen. Initially, it digests voluminous text corpora from Wikipedia to understand basic language structures. In the subsequent phase, it hones its skill set through specialized training on niche-specific texts like medical literature. Unlike its predecessors, BERT employs a bidirectional approach, considering both preceding and succeeding words for any given term. This nuanced attention to contextual intricacies equips BERT with an exceptional ability to differentiate semantic variations in words based on surrounding text.
These embedding methods are cornerstones in modern computational linguistics. With a solid understanding of how these embedding methods function as the building blocks of today’s tech-driven analysis, let’s pivot to examining their practical uses, exploring how they apply beyond theoretical constructs in real-world scenarios.
Practical Uses of Embeddings: Beyond Theory
Originally conceived within the realm of academia, Embeddings have evolved into indispensable elements for various machine learning applications in diverse domains, spanning Natural Language Processing (NLP), recommendation engines, and computer vision. Their prowess lies in facilitating the condensation of voluminous data into lower-dimensional spaces, thereby augmenting the capabilities of various machine-learning algorithms in practical applications. Uses of vector embeddings and word embeddings are manifold, extending from enhancing search algorithms to fortifying voice-activated digital assistants and elevating image recognition capabilities.
1. Enhancing Recommender Systems with Embeddings
In recommendation engines, the objective revolves around the accurate prediction of consumer preferences and evaluations for a range of products or services. Techniques like collaborative filtering and content-based filtering often surface as dominant approaches. Collaborative filtering capitalizes on historical user interactions to train models that generate recommendations. Contemporary systems integrate embeddings, for example, through singular value decomposition (SVD), to draw correlations between consumer behaviors and product attributes. Through matrix multiplication of user and item embeddings, these systems generate a predictive rating, which facilitates the algorithm in proposing items that align closely with a user’s historical preferences. Further, in sophisticated setups like YouTube’s recommendation algorithm, these embeddings feed into neural networks to predict user engagement metrics such as watch duration.
2. Semantic Search: Making the Web Understand You
Enhanced search capabilities arise from integrating embeddings generated using BERT algorithms, which excel at grasping words’ contextual relevance and semantic nuances. A query like “How to make pizza,” when processed by a BERT-optimized search engine, is analyzed to understand that the user seeks a guide for pizza preparation rather than a broad overview of the dish. The result is an elevated search output with markedly increased relevance and precision, thereby enriching the user’s interaction with the search engine.
3. Embeddings in Computer Vision: A New Horizon
In computer vision, vector and word embedding serve a crucial function by contextualizing varied scenarios. Take autonomous vehicles, for example; images captured from sensors transform embeddings, which act as data points for decision-making algorithms. This enables transfer learning, where a model can be trained on simulated visual data from video games rather than relying on costly real-world imagery. Companies like Tesla are pioneers in applying this methodology. Another avant-garde application lies in generative art platforms powered by artificial intelligence. These systems can translate textual descriptions into visual imagery through a multi-step transformation process involving embeddings. Specifically, both textual and visual data are mapped into a shared latent space via embeddings, enabling seamless conversions: Image to Embedding, Text to Embedding, Embedding to Text, and Image to Text transformations are all possible with this architecture, thereby broadening the applications of embeddings as a mediating layer between diverse data forms.
Essential Operations to Master in Embedding Handling
In advanced systems utilizing ML embeddings, it becomes imperative to incorporate the following functionalities for effective machine-learning outcomes.
1. The Art of Averaging in Embeddings
Within natural language processing, utilizing models like word2vec yields individual embeddings for separate terms. However, a more holistic representation, such as for entire sentences, becomes necessary. This composite representation can be synthesized by averaging the constituent word vectors. Similarly, for user behavior analytics within a recommendation engine, updating user embeddings by calculating the mean vector from the last N items interacted with is often beneficial, especially if the user profile hasn’t been refreshed promptly.
2. The Math of Addition and Subtraction in Embeddings
Vector arithmetic plays a pivotal role in tasks requiring contextual understanding. For instance, discerning a high-quality coat from a budget-friendly one can be achieved by computing the vector delta between the two. This stored delta is a reusable asset for recommending premium alternatives for any given item. Analogously, one can determine the dissimilarity vector between beverages like Coca-Cola and Diet Coca-Cola, which can then be applied to other beverages to infer variants that may serve as diet alternatives.
3. Finding the Nearest Neighbors
Identifying similarities via nearest-neighbor algorithms often proves invaluable. For example, user-specific embeddings can be devised in a recommendation system to yield the most pertinent item recommendations. Likewise, search engines can locate documents most analogous to a query through embedding similarity. Nonetheless, the computational intensity of nearest neighbor operations is a caveat. A brute-force approach can lead to O(N*K) complexity, where N represents the item count, and K signifies the embedding dimension. In many applications, the intricacy can be curtailed using approximate nearest neighbor algorithms, which reduce the time complexity to O(log(n)) while still delivering acceptable results.
Implementing Embeddings: The Technical Know-How
Integrating embeddings into live systems illuminates glaring deficiencies in existing data infrastructure frameworks. For instance, conventional databases and cache systems fall short when it comes to operations like nearest-neighbor lookups. Specialized approximate nearest-neighbor indices may offer partial solutions. Still, they often lack attributes like durable storage critical for seamless production deployment. Likewise, current Machine Learning Operations (MLOps) paradigms fail to offer specialized provisions for managing embeddings, particularly regarding version control, access, and training. To meet these nuanced requirements, there emerges an imperative for an embedding store: a database architecture inherently tailored to align with the complexities of machine learning workflows centered around embeddings.
1. Redis Paradigm: The Speedy Option for Embedding Storage
Renowned for its ultra-fast in-memory object storage capabilities, Redis simplifies storing and retrieving embeddings via keys. Nevertheless, its limitations become evident in the absence of innate embedding functionalities. Operations such as nearest-neighbor lookups, vector addition, and vector averaging necessitate external computation on the model service layer. Additionally, Redis integrates poorly into standard MLOps pipelines, lacking support for features like versioning, rollback capabilities, and state immutability. Moreover, the Redis client does not autonomously cache embeddings during the training phase, contributing to extraneous computational load and increased operational costs. The architecture also lacks partitioning capabilities for embeddings, impeding sub-indice creation.
2. Postgres Framework: The Robust Choice for Complex Needs
Postgres offers a more versatile yet latency-prone approach compared to Redis. Although it is extensible via plugins to execute certain vector operations, it falls short in optimized nearest-neighbor indexing. The inclusion of Postgres lookups within a model’s critical execution path often introduces undesirable latency, undermining real-time requirements. Furthermore, Postgres inadequately caches embeddings on the client side during the training process, significantly throttling training speeds.
3. S3 and Annoy/FAISS Methodologies: The Power Combo
Annoy, and FAISS typically come into play for operationalizing embeddings in systems requiring nearest-neighbor functionalities. While adept at building indices for approximate nearest-neighbor operations, they falter regarding durable storage or performing other vector-specific tasks. These solutions are generally piecemeal and often necessitate storing embeddings in S3 or equivalent object storage services to plug the remaining gaps. Consequently, this mandates that embeddings and ANN indices be loaded directly into the model as needed, complicating the embedding update process. This frequently culminates in a system replete with improvised rules for versioning and rollback management, highlighting the need for a comprehensive embedding store to encapsulate these functionalities.
Embeddings in ChatGPT
ChatGPT operates at the nexus of machine learning and natural language processing technologies to autonomously generate textual content. When fed a command, such as “Compose a feline-centric verse,” the sentence undergoes tokenization. Each lexeme—e.g., “Compose,” “feline-centric,” and “verse”—is individually isolated.
Machine intelligence must transform these tokens into a numerical format interpretable since alphanumeric characters hold no inherent meaning for computational systems. To this end, tokenized text is transmuted into ChatGPT embeddings. Via a neural architecture trained to deduce a token’s semantic significance from its neighboring tokens’ milieu, these embeddings condense semantic information into an array of numerical values. Thus, words or phrases with similar meanings are numerically aligned.
How ChatGPT Leverages Embeddings for Better Conversations?
ChatGPT is a specialized derivative of causal language models that employs a transformer neural architecture to generate a chronologically ordered token sequence. Transformers excel at parallelized data sequence manipulation and employ an ‘attention mechanism’ to evaluate the relevance of each token in a given command prompt for response formulation. To adequately train these transformer tiers, terabytes of textual data are required, demanding thousands of GPUs and an extended temporal investment.
During predictive operations, input embeddings are funneled through computational operations across multiple transformer layers, resulting in refined output embeddings. These output embeddings are then reverted into text tokens, constituting the model’s final response. ChatGPT embeddings leverages an autoregressive technique for text production; after generating each token, it reintegrates it into the original prompt for recursive processing until a specific “terminus” token signals the completion of text generation.
OpenAI’s specific embedding implementation is vital to ChatGPT’s operational efficacy. User-initiated prompts transform into tokenized units and further into numerical embeddings via transformer architecture. Semantically akin words manifest as numerically similar embeddings. Subsequently, these embeddings navigate through successive transformer layers trained for selective ‘attention,’ culminating in issuing a terminal token that marks the response as complete.
Concisely, embeddings in ChatGPT function as multidimensional numerical vectors encapsulating semantic and syntactic textual elements, fundamental to the neural network’s capacity to fabricate coherent and contextually apt responses. Deploying ChatGPT usually involves utilizing an antecedently trained language model—say, GPT-2 or GPT-3—already calibrated on extensive textual datasets. The prompt initializes the token-to-embedding transformation, which is indispensable for response generation.
Liked this blog? We have another interesting blog for you to read How to Connect LLM to External Sources Using RAG?
Creating Embeddings with Markovate
At Markovate, we’ve redefined the complexities traditionally associated with creating embeddings. Leveraging state-of-the-art algorithms, we facilitate the seamless transformation of text into numerical vectors—embeddings that are the bedrock of machine learning and natural language processing initiatives. These vectors are designed to retain the rich semantic context of your textual data, proving invaluable in applications ranging from chatbots to recommendation engines.
We offer an integrated platform where the lifecycle of an embedding—from its inception to its application—is managed effortlessly. Our algorithms are meticulously optimized for high-dimensional data, ensuring that your embeddings are computationally efficient and information-rich. With us, the journey to mastering embeddings isn’t about navigating a labyrinth of technical challenges; it’s about harnessing the potential of AI to solve real-world problems. So, with Markovate, the narrative shifts from ‘how to make it work’ to ‘what wonders can we achieve with it.’
All Your Embedding Questions Answered
1. What Constitutes Embedding Mechanisms in Natural Language Processing?
Embedding mechanisms in Natural Language Processing (NLP) are advanced techniques for converting lexical units into real-valued vector representations. This has considerably enhanced machine capabilities in understanding and processing textual data.
2. How Do Embeddings Operate Within the Realm of Artificial Intelligence?
In Artificial Intelligence (AI), embeddings act as computational frameworks that transform real-world entities into numerical vectors, whether words, images, or sounds. These numerical vectors are pivotal for carrying out similarity computations and pattern recognitions, making them an indispensable component of AI operations.
3. What’s Different Between Embeddings and Large Language Models?
Embeddings are foundational elements that constitute large language models (LLMs). While both are integral parts of the NLP ecosystem, the primary function of embeddings is the vectorization of individual entities. On the other hand, LLMs act as a higher-order architecture that integrates these embeddings to perform more complex language comprehension tasks.
4. What is Utilization of Embeddings in GPT and BERT Architectures?
GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers) utilize state-of-the-art embedding techniques. These techniques, supported by Transformer architecture, allow these models to surpass previous generations’ ability to understand and manipulate language.
5. What are the Mechanisms Underlying the Functionality of AI Embeddings?
In an AI setting, embeddings are generated from model parameters or weights. These embeddings perform a dual function: encoding input data into machine-readable vectors and decoding machine-generated output back into human-comprehensible language. This functionality enables the model to discern semantic and syntactic relationships among tokens, producing more relevant and coherent text.