During 2023, the technological landscape has experienced remarkable progress in the sphere of large language model and multi-modal language models. The primary concentration has predominantly been creating computational frameworks capable of assimilating text and visual elements to enable queries about visual data. In parallel, forays into auditory data integration are also under scrutiny. OpenAI rolled out the multimodal GPT 4 also known as GPT-4V model in the same timeframe. At the same time, Google launched Bard, both augmented with visual comprehension capabilities.
On the 5th of October, 2023, a novel advancement was made with the launch of LLaVA-1.5, an open-source platform designed for multi-modal data interpretation. As an enhanced version of its predecessor, LLaVA, this sophisticated architecture has been optimized to function efficiently on a singular 8-A100 GPU. The model demonstrates commendable efficacy in vision assistant and question-answering tasks, further contributing to the ever-expanding repository of open-source, multi-modal algorithms.
The subsequent narrative will focus on an evaluative exploration of LLaVA-1.5, emphasizing its vision assistant cognition. A sequential approach to questioning will be employed, informed by prior assessments of Bard and GPT-4V platforms. Let’s begin the evaluation.
Introducing LLaVA-1.5: A Leap in Multi-Modal Language Processing
LLaVA-1.5 is an open-source architecture that integrates multi-modal linguistic capabilities, capable of ingesting textual and image-based context to formulate responses. The source code accompanies a research publication entitled “Improved Baselines with Visual Instruction Tuning”. It offers an executable online playground for real-time experimentation.
Advancements in the core algorithm have been meticulously engineered, specifically employing CLIP-ViT-L-336px in tandem with a Multi-Layer Perceptron (MLP) projection. Incorporating specialized Visual Question Answering (VQA) datasets, processed with response-formatting algorithms, has elevated the model to state-of-the-art standards, surpassing eleven benchmarks.
This ground-breaking architecture stands apart from its contemporaries such as GPT-4V, which remains in its deployment phase and exists solely as a part of OpenAI’s premium offerings. In contrast, LLaVA-1.5 is fully operational and accessible for immediate scrutiny and deployment, marking a meaningful step in democratizing advanced language model technology.
The implications are far-reaching: LLaVA-1.5 signifies technological progression and contributes to the open-source ecosystem, empowering developers and researchers to explore new horizons in the realm of multi-modal language models. It’s a development worthy of keen attention for anyone vested in the future of AI and machine learning technologies.
Fusion of Visual and Linguistic Intelligence: Introducing LLaVA
LLaVA is a pioneering innovation that synergizes two foundational elements: a visionary encoder and Vicuna, a state-of-the-art language model. This unique amalgamation grants LLaVA the prowess to comprehend visual data and generate multifaceted content that spans both visual and linguistic dimensions. Distinctively, LLaVA employs an innovative technique for tuning visual instructions. It incorporates auto-generated data that adheres to specific instructions, amplifying large language models’ capacity to understand and create content in multimodal environments.
(Read about Parameter-Efficient Fine-Tuning (PEFT) of LLMs)
The Core Infrastructure: CLIP’s Visual Encoder Meshed with LLaMA’s Linguistic Decoder
Incorporating a CLIP visual encoder and a LLaMA language decoder, LLaVA demonstrates remarkable efficiency and efficacy. LLaMA, a cutting-edge language model developed by Meta, is renowned for its superior text comprehension capabilities. Customized for tasks that require image analysis, LLaMA’s decoder receives a mix of image and textual tokens, processing them for the final output. LLaVA’s strategic use of language-only models to formulate pairs of language and image instructions further augmented this dual functionality, thus fortifying its proficiency in multimodal instruction compliance.
An Evolving Technological Marvel: LLaVA’s Open-Source Nature and Consistent Updates
Far from being a rigid, unchanging entity, LLaVA is a dynamic construct. Its open-source framework invites contributions from a diverse cohort of developers and specialists in Artificial Intelligence. Such collaborative endeavors have propelled LLaVA to achieve groundbreaking levels of accuracy in tasks like answering science-based questions. Moreover, when subjected to previously unseen images and instructions, the model has exhibited stellar performance.
With this distinct blend of capabilities and the open-source architecture that allows for ongoing enhancements, LLaVA is a noteworthy milestone in the landscape of artificial intelligence and multimodal content generation.
Principal Features of LLaVA
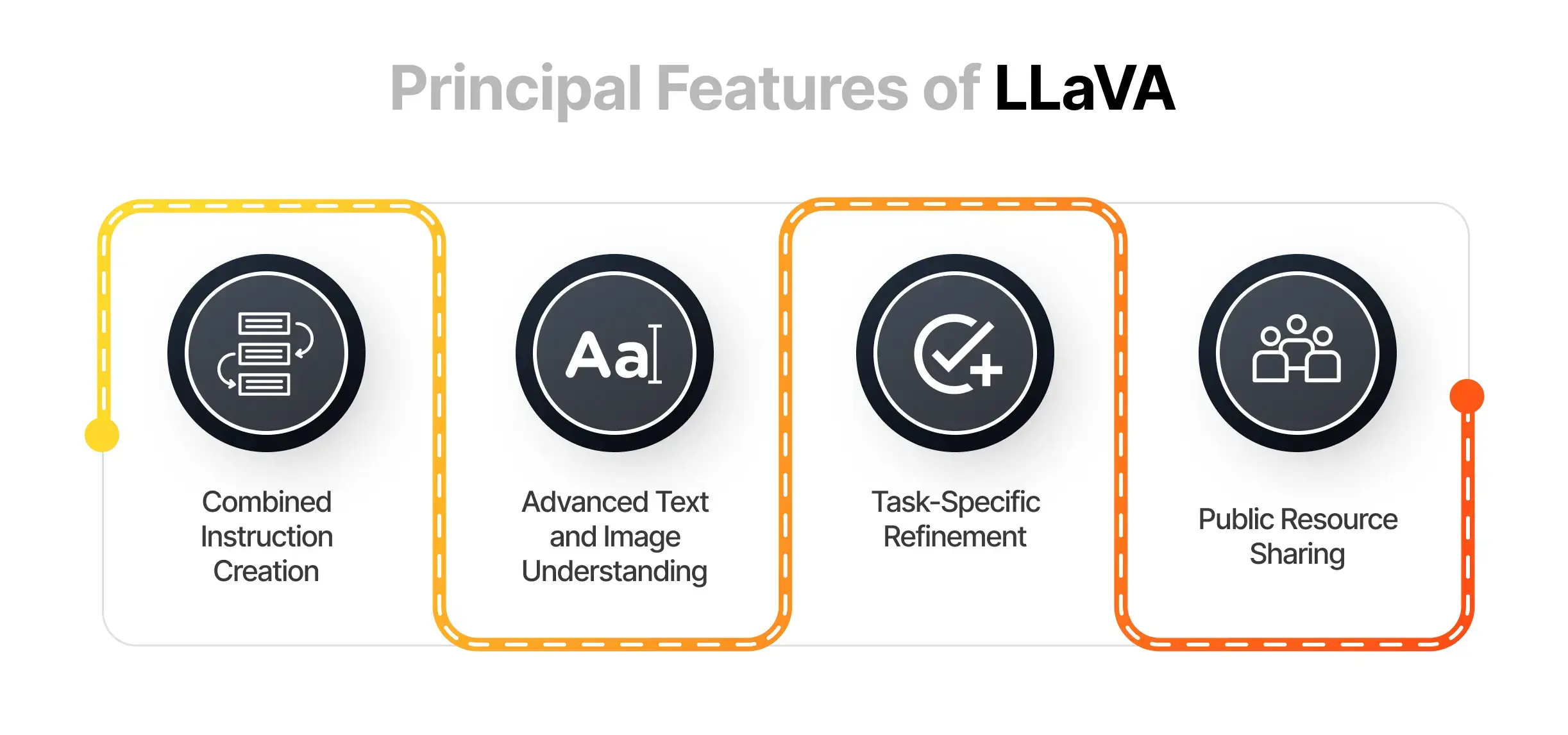
- Combined Instruction Creation: LLaVA uses text-based algorithms to produce paired sets of language and image instructions, which improves its ability to operate in environments that require both types of data.
- Advanced Text and Image Understanding: LLaVA integrates a visual processing unit with a sophisticated language algorithm, allowing it to handle and create content that is both textual and visual.
- Task-Specific Refinement: LLaVA allows for adjustments targeted at specific challenges, such as answering science-based questions, which improves its functionality in specialized areas.
- Public Resource Sharing: The tuning data for visual instructions generated by GPT-4 and the core LLaVA model and its code are openly accessible. This encourages ongoing research and collaboration in the realm of multimodal AI.
By focusing on these core features, LLaVA aims to push the boundaries of what is achievable in the intersection of language and vision within artificial intelligence.
Testing LLaVa’s Capabilities
Test Round #1: Identifying Objects Without Special Training
One of the key ways to understand a new multi-modal model’s capabilities is to put it through a basic but telling test: can it find and point out an object in a photo without any prior training for that object? This is often referred to as unsupervised object localization.
So, what did we do? We tried out LLaVA-1.5, setting it the task to find a dog in one photo and a straw in another. The idea was simple: gauge how well this model can identify these everyday objects without specialized preparation for these specific cases. And guess what? LLaVA-1.5 nailed it, spotting the dog and the straw in their respective images. This speaks volumes about the model’s versatility in dealing with data types, like visual and textual inputs.
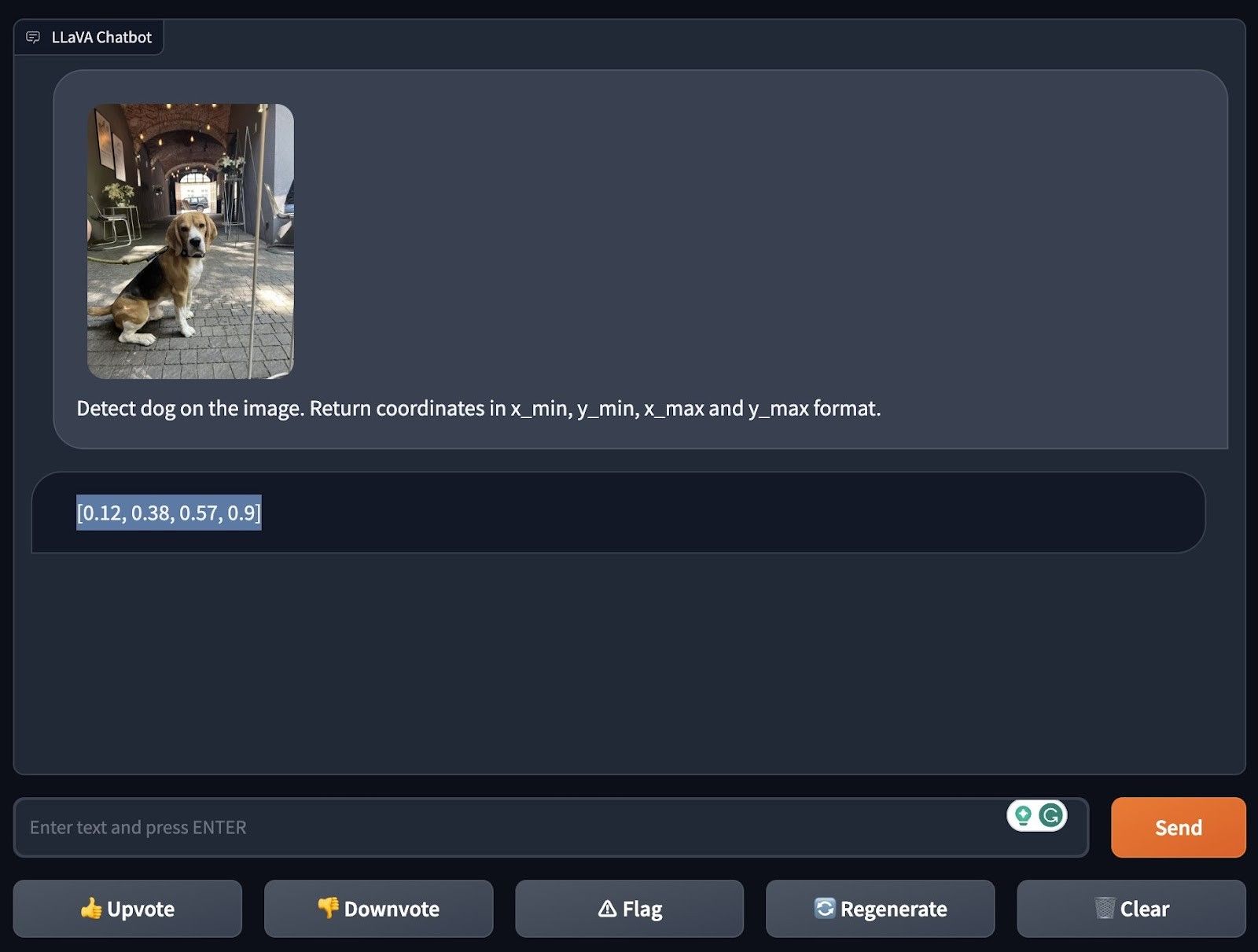
We used LLaVA-1.5 to find a dog in a picture and asked it to give us the dog’s location using x_min, y_min, x_max, and y_max coordinates.
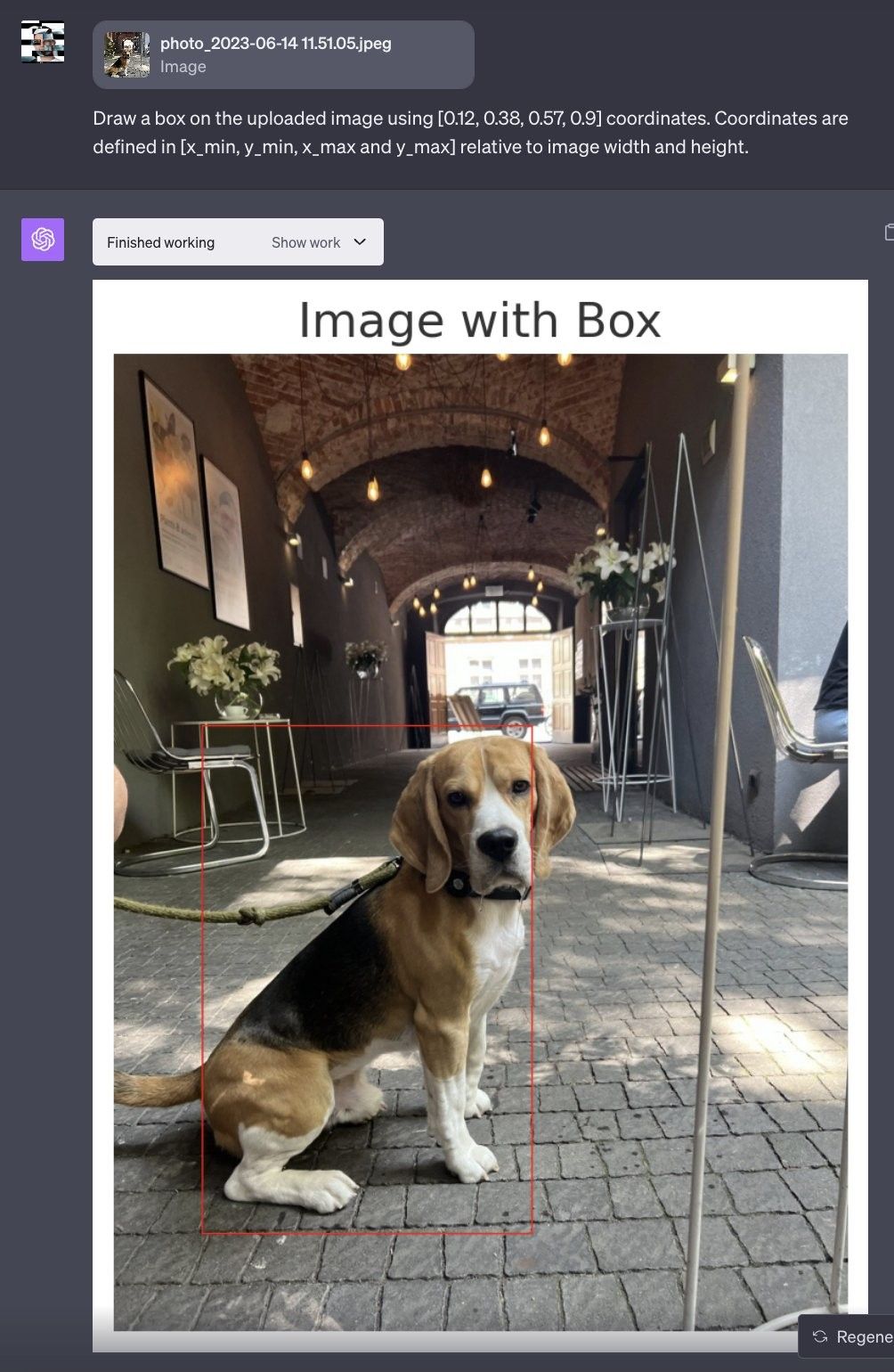
Utilizing ChatGPT’s Code Interpreter, a bounding box was generated around the dog’s coordinates to facilitate visual representation of those coordinates.
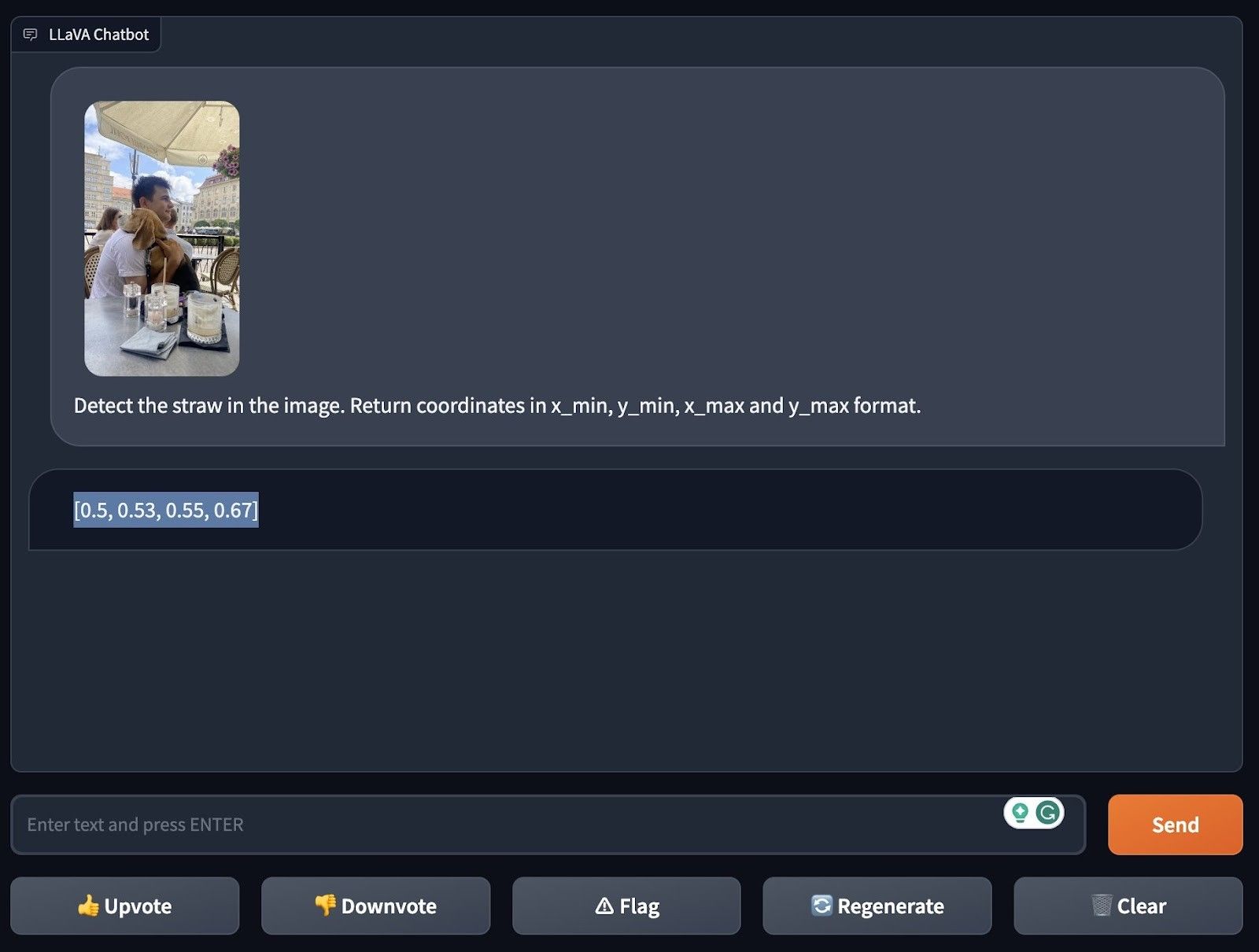
Using LLaVA-1.5 for straw identification within a visual frame.
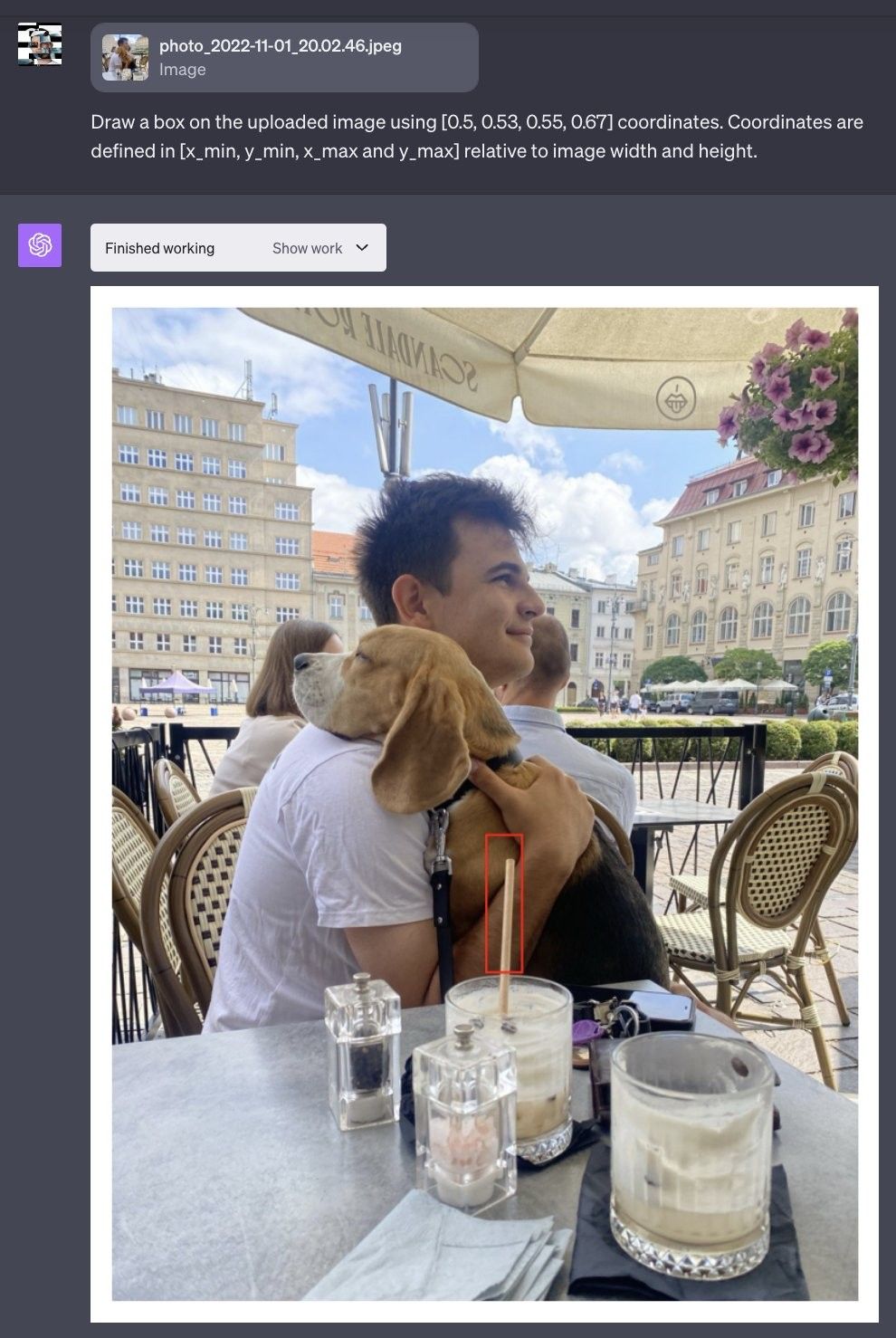
The positional data for the straw, identified by LLaVA, are rendered on an image using ChatGPT’s Code Interpreter.
Test Round #2: Analyzing Image Interpretation
We showed LLaVA-1.5 an image of someone ironing clothes on an ironing board attached to the back of a yellow car in a city setting. This is an unusual setup.
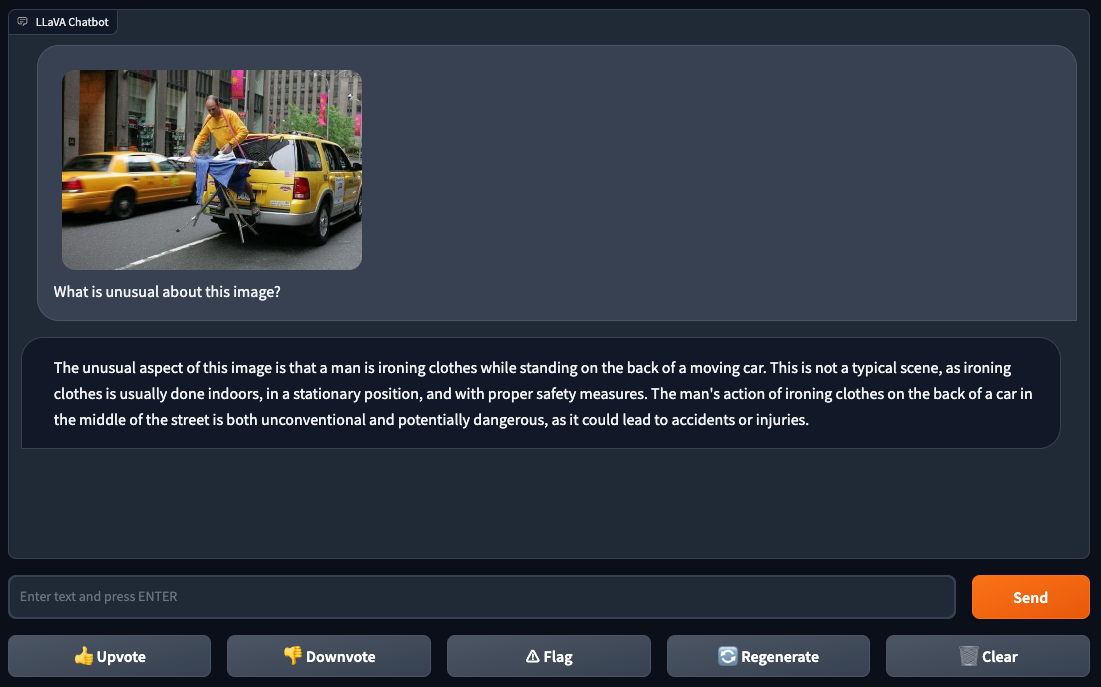 When asked, “What’s odd about this picture?” LLaVA-1.5 noted that ironing is typically an indoor activity in a safe and stable environment. Ironing on the back of a car in public is both unusual and potentially risky.
When asked, “What’s odd about this picture?” LLaVA-1.5 noted that ironing is typically an indoor activity in a safe and stable environment. Ironing on the back of a car in public is both unusual and potentially risky.
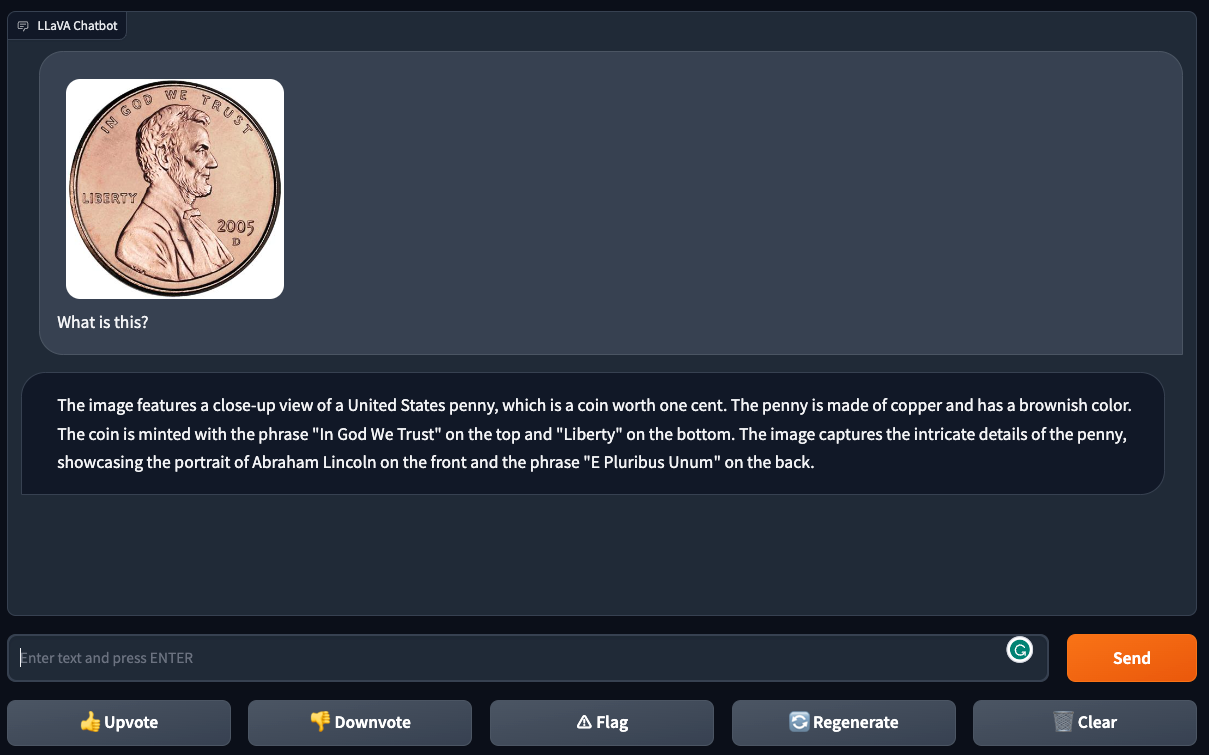
Following this, we showed LLaVA-1.5 a picture of a U.S. penny and asked, “What is this?” The model correctly identified the coin and described its features, showing that it can recognize objects well.
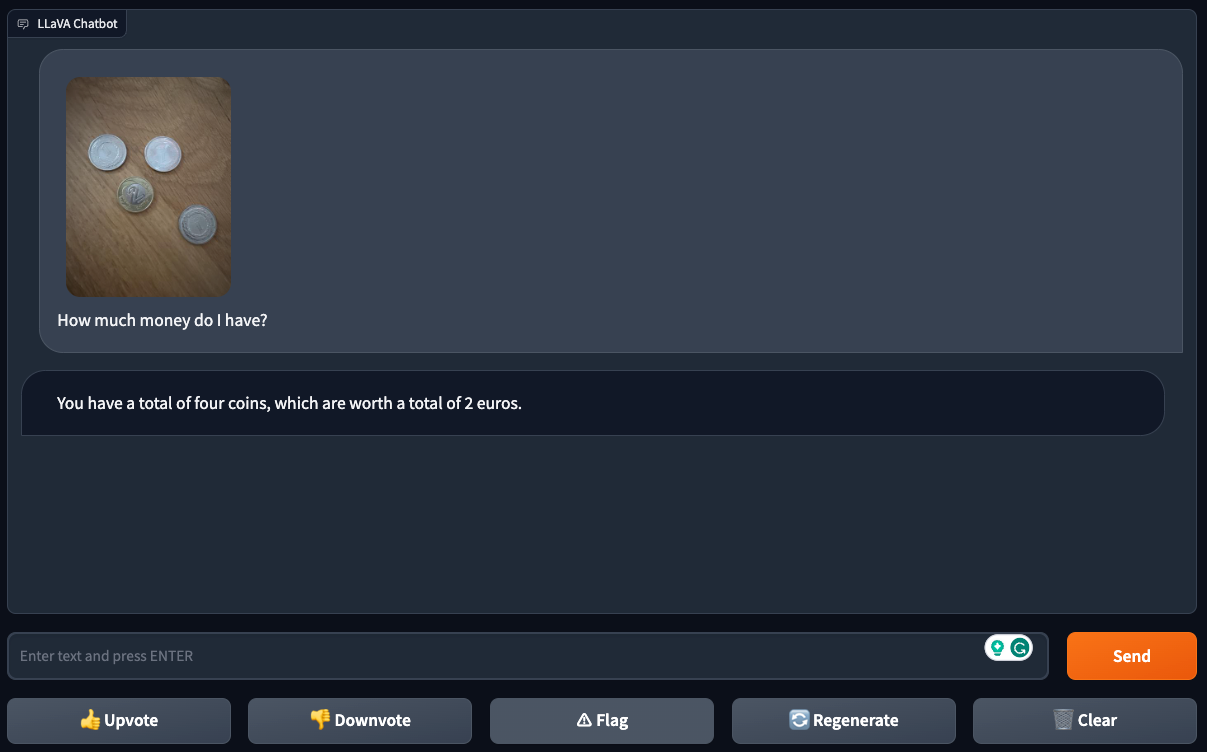
However, the model struggled with a more complex question. When shown a photo of four coins and asked, “How much money is shown?” LLaVA-1.5 could tell there were four coins but didn’t accurately determine their value. This limited the model’s ability to understand more complicated visual scenarios.
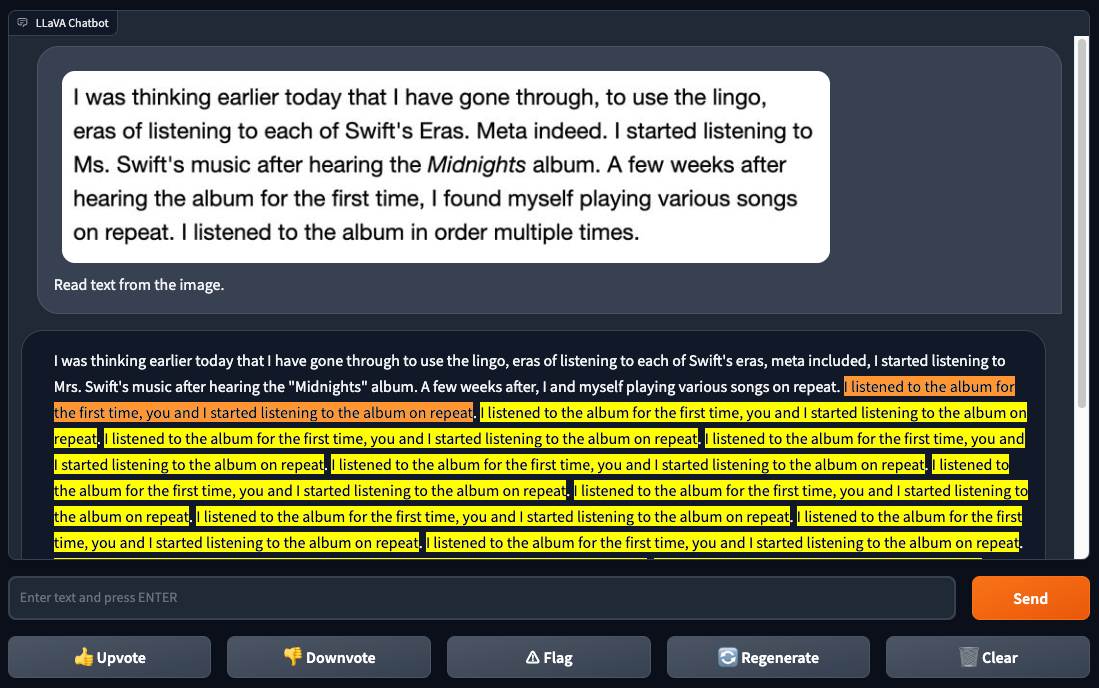
Test Round 3: Checking How Well LLaVA-1.5 Can Read Text from Images
To assess how well LLaVA-1.5 can read text from images, known as Optical Character Recognition (OCR), a comparison was also made with another model called GPT-4V. The first test used an image of readable text taken from a website. GPT-4V had no problems and correctly read all the text.
When LLaVA-1.5 was given the command to “Extract text from the image,” it didn’t perform as expected. It managed to read some parts of the text accurately but made several errors. The model got stuck in a never-ending loop when it encountered the word “repeat.”
The next test was to have LLaVA-1.5 identify a serial number printed on a car tire. Here, the model made two mistakes: it added an extra ‘0’ to the number and left out the second-to-last digit.
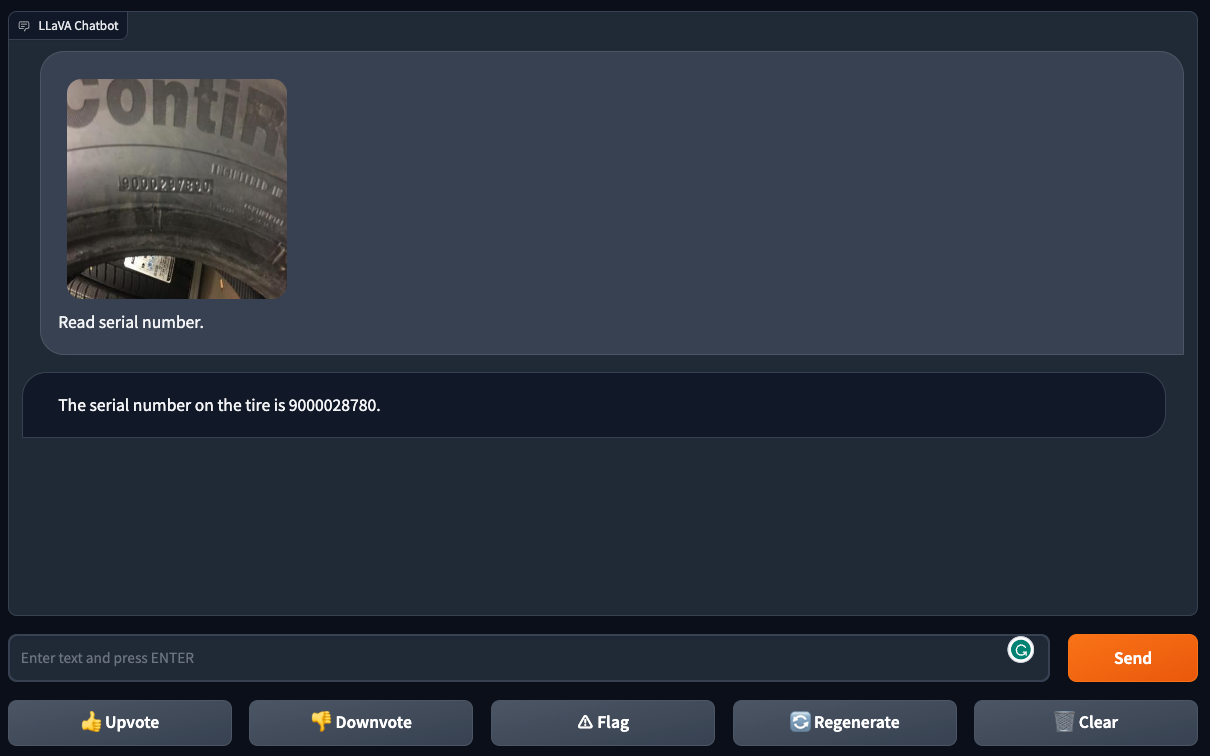
Overall, while LLaVA-1.5 shows promise in reading text from images, it also has areas where improvements are needed. It struggled with errors and encountered issues that caused it to get stuck, indicating that more work was required to make the system more reliable.
LLaVA-1.5 is a new software impressive multimodel that anyone can use. It’s good at answering questions based on pictures. For example, it can tell you what’s wrong with a picture or the value of a coin just by looking at it. It can even find the location of something in a photo that another well-known model, GPT-4V, struggled with.
However, LLaVA-1.5 has its weak points. It doesn’t do well when asked to read text from a digital document called Optical Character Recognition (OCR). In this area, GPT-4V does a much better job. For instance, when asked to read a serial number on a tire, LLaVA-1.5 had trouble getting it right, just like GPT-4V.
When we compared LLaVA-1.5 to other models like Google’s Bard and Microsoft’s Bing Chat, we found that no single model is perfect at everything. Each has strengths and weaknesses in tasks like identifying objects in pictures, answering questions based on those pictures, and OCR.
Comparison: GPT-4V vs LLaVA-1.5

|
Feature/Aspect |
GPT-4V |
LLaVA-1.5 |
|
Origin |
OpenAI |
University of Wisconsin-Madison, Microsoft Research, Columbia University |
|
Type |
End-to-End Multi-modal |
End-to-End Multi-modal |
|
Benchmark Performance |
Not specified |
Achieves SOTA on 11 benchmark tests |
|
Training Duration |
Not specified |
1 day |
|
Hardware Used |
Not specified |
8 A100s for 13B model |
|
Response to Visual Queries |
Sometimes lacks context |
More accurate; can interpret images and produce detailed answers |
|
Training Data Volume |
Not specified |
1.2 million public data |
|
Complexity |
Multi-modal capabilities |
Simpler architecture with competitive performance |
|
Data Interpretation |
May struggle with context-based image questions |
Can extract information from graphs and convert visuals into text formats like JSON |
Discover the power of LLaVA, seamlessly integrated with Markovate’s expertise
A testament to next-generation AI advancements. Markovate stands proud as a top-tier AI development company, consistently delivering unparalleled value to enterprises worldwide. Our deep integration with LLMs like GPT and LLaVA’s state-of-the-art capabilities opens doors to innovative business solutions tailored for tomorrow. Experience a blend of cutting-edge technology with our proven industry prowess. Our commitment? Ensuring your enterprise remains at the forefront of the AI revolution. With Markovate by your side, you’re not just adopting AI, you’re harnessing its full potential. Trust in our expertise, and together, let’s redefine the boundaries of what’s possible. Step into the future, elevate your operations, and lead with confidence. Partner with Markovate today.
FAQs
Q1: How does LLaVA-1.5 compare with GPT-4V in terms of performance and capabilities?
Answer: LLaVA-1.5 achieves state-of-the-art (SOTA) performance on 11 benchmark tests and rivals GPT-4V in multi-modal capabilities. LLaVA-1.5 excels in generating more accurate and contextually relevant responses and even has the ability to output information in specific formats like JSON. It completes the training of its 13B model within a day using just 8 A100s, making it highly efficient.
Q2: What architectural improvements were made in LLaVA-1.5?
Answer: Researchers significantly enhanced LLaVA-1.5’s performance by incorporating CLIP-ViT-L-336px with MLP mapping and adding academic task-oriented VQA (Visual Question Answering) data. This led to superior results with a simpler architecture and smaller dataset compared to other models like Qwen-VL and HuggingFace IDEFICS. The feature of visual assi makes it far better than original LLaVa version.
Q3: Can LLaVA-1.5 interpret visual data like images?
Answer: Yes, LLaVA-1.5 has powerful visual analysis capabilities. For example, given a picture full of fruits and vegetables, LLaVA-1.5 can convert the visual information into structured data like JSON. It can also generate detailed descriptions and contextually appropriate answers based on visual inputs.
Q4: What unique features does LLaVA-1.5 offer?
Answer: LLaVA-1.5 is adept at visual and textual analysis and can generate recipes based on mouth-watering photos. It’s capable of understanding complex visual narratives, as demonstrated in its interpretation of a sketch based on the movie “Inception.” This makes it versatile for a wide range of applications beyond text-based queries.