As the world of machine learning continues to expand, constructing efficient MLOps pipelines has become increasingly crucial for businesses. In this blog post, we will delve into the key components and benefits of implementing an MLOps pipeline that can streamline your machine learning operations.
We’ll discuss how to establish robust automated CI/CD systems with data validation processes and explore the role of Feature Store in ML pipelines. Furthermore, you’ll learn about continuous testing best practices for ML pipelines, including data ingestion strategies and pre-processing techniques for improved accuracy.
Lastly, we will cover essential collaboration aspects between Data Scientists and Machine Learning Engineers as well as reinforcement learning hyperparameter fine-tuning (RLHF) techniques that can enhance your MLOps pipeline performance significantly.
MLOps Pipeline and Its Importance
MLOps, or Machine Learning Operations, bridges the gap between data science and software engineering by automating both machine learning and continuous integration/continuous deployment pipelines. This approach helps businesses deploy solutions that unlock previously untapped sources of revenue, save time, and reduce costs.
Automating ML processes to increase efficiency
Implementing MLOps solutions with tools like TensorFlow Extended (TFX) or MLflow enables organizations to construct ML pipelines capable of handling tasks such as feature engineering, model training, validation, and monitoring machine learning models in production environments. This automation enables teams to deploy their projects while lowering operational costs rapidly.
Bridging the gap between data science and software engineering
ML projects often fail due to a lack of collaboration between data scientists who develop algorithms and engineers responsible for deploying them into production systems. By unifying DevOps methodologies with MLOps principles like pipeline deployment triggers or multi-step pipeline components when an offline-trained ML model needs updating based on fresh data input, companies can ensure successful machine learning project outcomes across all stages from development through deployment.
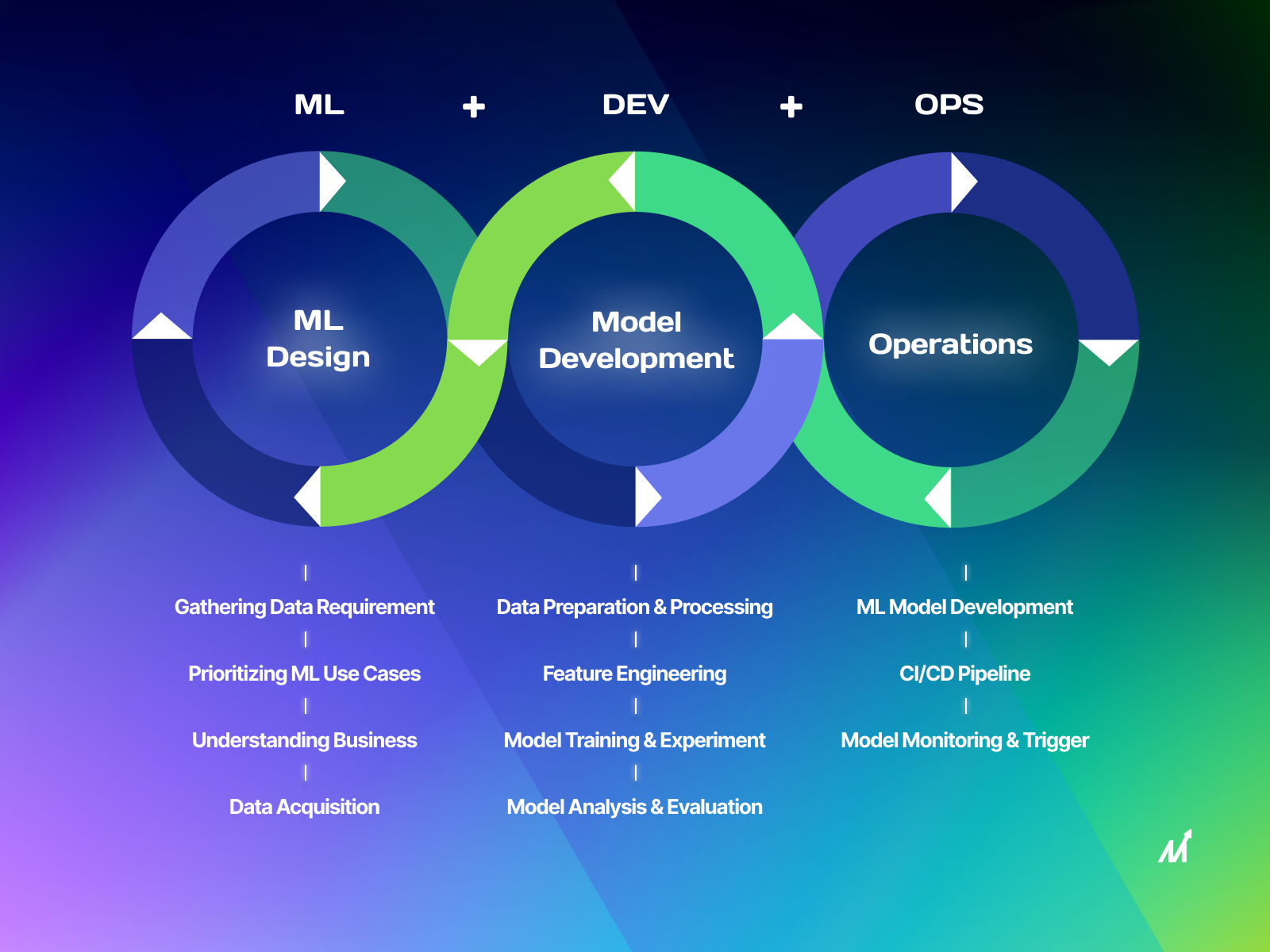
ML Pipeline Automation
ML pipeline automation is a crucial component of MLOps. It involves automating the entire machine learning lifecycle, from data pipeline to model deployment and prediction service. By automating these processes, organizations can achieve continuous delivery and reduce the time it takes to get their models into production.
Monitoring Machine Learning Models
Monitoring machine learning models is another important aspect of MLOps. It involves tracking the performance of production models and ensuring they continue to provide accurate predictions over time. Tools like TensorFlow Serving or KFServing can help teams monitor their models and make updates as needed.
Implementing MLOps
Implementing MLOps requires a combination of tools, processes, and people. It involves unifying data scientists and software engineers, implementing automation pipelines, and using MLOps tools like MLflow or TFX. By doing so, organizations can unlock the full potential of their machine-learning projects and achieve successful outcomes.
Key Takeaway: MLOps bridges the gap between data science and software engineering by automating machine learning and continuous integration/deployment pipelines. By unifying DevOps methodologies with MLOps principles, organizations can ensure successful outcomes across all stages of development through deployment. Implementing MLOps requires a combination of tools, processes, and people to unlock the full potential of machine learning projects.
Key Components in an MLOps Data Pipeline
MLOps pipelines are essential for streamlining the machine learning lifecycle and ensuring seamless collaboration between data scientists and engineers. Let’s take a look at some of the critical components of an MLOps pipeline:
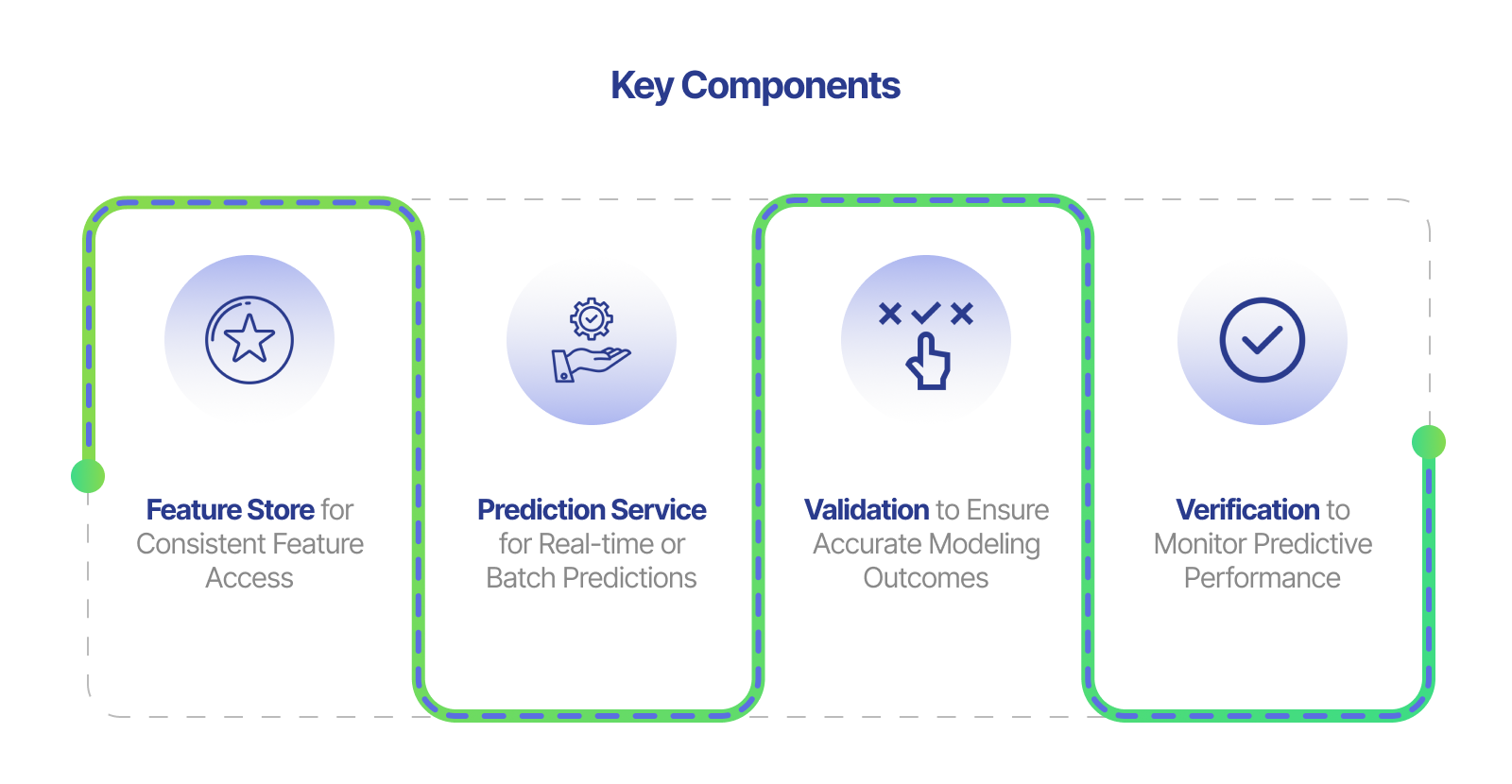
Feature Store for Consistent Feature Access
A Feature Store is a centralized repository that simplifies feature engineering, reduces redundancy, and ensures that both offline-trained ML models and live prediction services use the same set of features. This component is crucial for achieving continuous delivery and unifying DevOps and data scientists.
Prediction Service for Real-time or Batch Predictions
The Prediction Service component allows businesses to rapidly deploy their machine learning solutions into production environments while maintaining scalability and performance. This service is responsible for serving predictions in real-time or batch mode based on trained ML models.
Validation to Ensure Accurate Modeling Outcomes
Validation plays a vital role during training phases by ensuring accurate modeling outcomes before deploying them into production settings. This process includes techniques such as cross-validation, hyperparameter tuning, model selection, and evaluation metrics tracking. Proper validation is crucial for a successful machine learning project.
Verification to Monitor Predictive Performance
Verification focuses on monitoring the predictive performance of ML models over time after deployment into production settings. This component helps identify potential issues, such as model drift or data quality problems, that may affect the accuracy and reliability of predictions. Monitoring machine learning models is essential for lowering operational costs and maintaining successful machine learning projects.
Achieving Level 1 ML Pipeline Automation with CI/CD Systems
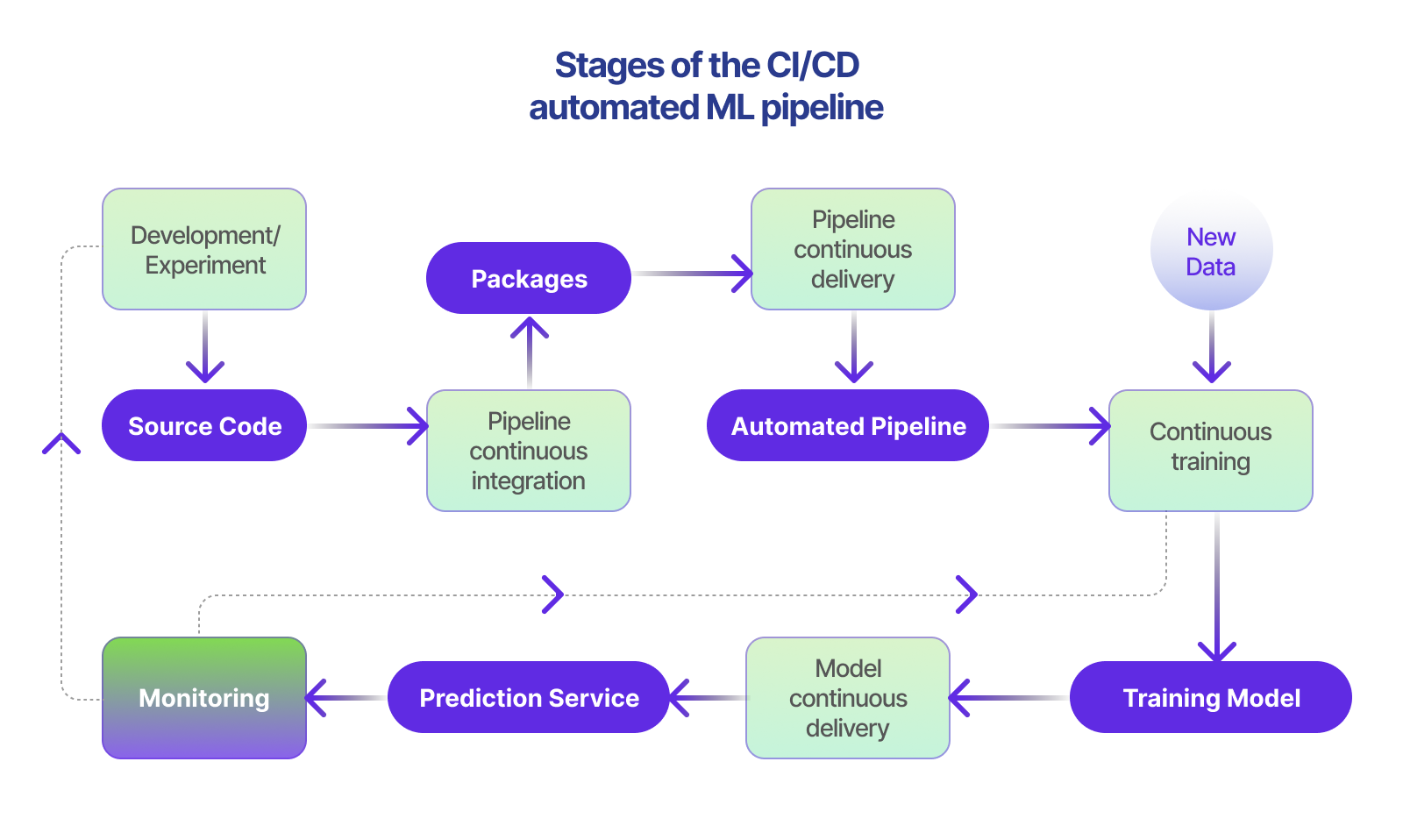
To achieve Level 1 ML pipeline automation, it’s crucial to include data validation and model validation steps within robust automated CI/CD systems capable of unit testing feature engineering logic. Incorporating a feature store can be beneficial but isn’t strictly necessary. By following these best practices for CI/CD and CT (Continuous Testing), organizations can streamline their ML processes while maintaining high-quality results.
Including Data Validation in CI/CD Systems
Data validation is essential in the machine learning pipeline to ensure the quality of input data used for training models. Integrating this process into your existing CI/CD system helps maintain consistency across different stages, reducing errors caused by inconsistencies or incorrect assumptions about the underlying data structure.
Model Validation as Part of the Automation Process
Model validation involves evaluating machine learning models’ performance against predefined metrics such as accuracy, precision, recall, or F1 score. Including this step within your CI/CD pipelines allows you to automatically test new versions of your model before deploying them to production environments. This way, you can catch potential issues early on and ensure that only well-performing models are deployed.
- Data Scientists: Focus on creating high-quality features and ensuring data validation is integrated into the CI/CD pipeline.
- Machine Learning Engineers: Implement model validation steps within the automation process to ensure that only well-performing models are deployed in production environments.
Incorporating these practices for data and model validation within your ML pipeline automation can lead to more efficient workflows, lower operational costs, and better overall performance of machine learning systems in production settings. By implementing MLOps solutions and tools, you can construct and implement ML pipelines that unify DevOps and data scientists, rapidly deploy and manage machine learning models, and monitor them throughout their lifecycle. With these best practices, you can achieve continuous delivery and a successful machine learning project.
Key Takeaway: To achieve Level 1 ML pipeline automation, organizations must include data and model validation steps in their CI/CD systems. This ensures consistency across different stages of the machine learning pipeline, reduces errors caused by incorrect assumptions about data structure, and catches potential issues early on to ensure only well-performing models are deployed in production environments. By implementing MLOps solutions and tools, businesses can streamline workflows, lower operational costs, and improve overall performance of machine learning systems.
Collaboration Between Data Scientists & Machine Learning Engineers
In the rapidly evolving world of machine learning and data science, collaboration between data scientists (DSes) and machine learning engineers (MLEs) is crucial for successful project outcomes. As hybrid cloud environments add another layer of complexity to IT management, it becomes increasingly important for these professionals to work closely together throughout the development process.
Improving Code-Writing Skills for Data Scientists
Data scientists should focus on improving their code-writing skills to contribute directly to production-ready systems. By doing so, they can ensure that their models are efficiently integrated into the overall software architecture. This not only helps in reducing bottlenecks but also promotes a smoother transition from research prototypes to live pipeline triggers within an organization’s ML infrastructure.
Machine Learning Engineers Focusing on Product and Business Aspects
On the other hand, MLEs need to consider more product/business questions when designing models. Understanding customer requirements, market trends, and organizational goals can help them develop better solutions that align with company objectives. Additionally, this enables MLEs to make informed decisions regarding model deployment strategies, such as offline-trained ML model integration or multi-step pipeline setups, depending on specific use cases.
To achieve continuous delivery in ML Ops projects, both DSes and MLEs must be well-versed in various MLOps tools like feature engineering techniques, prediction service platforms, and monitoring machine learning models’ performance metrics. This will ultimately lead to lower operational costs while ensuring high-quality results. Successful machine learning projects require unifying DevOps and data scientists to implement MLOps solutions that construct ML pipelines, implement MLOps tools, and achieve MLOps levels 0, 1, and 2.
Integrating MLOps Components with Traditional DevOps Methodologies
Integrating ML pipeline automation with traditional DevOps methodologies like Continuous Integration & Deployment (CI/CD) can help teams achieve seamless collaboration and accelerated innovation across their ML projects. By incorporating essential MLOps tools, such as feature engineering solutions, model training platforms, and prediction services into existing CI/CD pipelines, data scientists and software engineers can work together more efficiently and effectively.
Seamless Collaboration Between Data Science and Engineering Teams
With MLOps, data scientists can rapidly explore new ideas while maintaining production-level quality standards. By leveraging the expertise of both data science professionals and software engineers, machine learning models are developed more efficiently and effectively. Incorporating tools like Feature Store, Prediction Service, and Validation & Verification into the workflow structure promotes efficiency in software development processes.
Accelerated Innovation Through Integrated Workflows
- Data Pipeline: Implementing an end-to-end data pipeline helps automate tasks like preprocessing raw input data for analysis or transforming it into features suitable for machine learning algorithms.
- MLOps Level 1 Automation: Achieving level 1 automation requires incorporating unit testing for feature engineering logic within robust automated CI/CD systems capable of validating both data inputs and model outputs during each iteration cycle.
- MLOps Level 2 Monitoring: To ensure ongoing success in live environments, monitoring machine learning models becomes crucial at this stage – enabling organizations to detect potential issues before they escalate into larger problems affecting overall system performance or customer satisfaction levels.
By unifying DevOps and MLOps practices, organizations can create a cohesive environment that fosters collaboration between data scientists and software engineers, resulting in faster development cycles, lower operational costs, and more successful machine learning projects. Implementing MLOps solutions and tools like automation pipelines, pipeline deployment, and live pipeline triggers can help achieve continuous delivery of machine learning models in production environments.
Key Takeaway: Integrating MLOps components with traditional DevOps methodologies can help teams achieve seamless collaboration and accelerated innovation across their ML projects. By unifying DevOps and MLOps practices, organizations can create a cohesive environment that fosters collaboration between data scientists and software engineers, resulting in faster development cycles, lower operational costs, and more successful machine learning projects.
FAQs in Relation to Mlops Pipeline
What is a Pipeline in MLOps?
A pipeline in MLOps is the complete process of developing, deploying, and maintaining machine learning models, including data ingestion, preprocessing, model training, validation, deployment for inference services, and monitoring performance.
What are the Benefits of an MLOps Pipeline?
- Get faster development and deployment.
- Improve collaboration between teams.
- Enhance model quality through continuous testing.
- Easily scale and maintain your models.
- Ensure compliance with regulatory requirements.
What are the Three Stages of MLOps?
The three stages of MLOps are Model Development, Model Deployment, and Model Management, which involve creating ML algorithms based on data, integrating trained models into production systems, monitoring performance metrics, and updating or retraining as needed.
What is Mostly True About MLOps but Not DevOps?
MLOps primarily manages machine learning workflows, while DevOps emphasizes software development processes. Unlike DevOps, which deals with code versioning only, MLOps handles both code and data versioning.
Conclusion
Streamlining machine learning processes through an MLOps pipeline is crucial for any organization, including automated CI/CD systems, continuous testing, collaboration, feature stores, and real-time prediction services.
Optimizing models for improved accuracy is possible by incorporating reinforcement learning hyperparameter fine-tuning techniques into the pipeline.
Efficient MLOps pipelines lead to faster time-to-market for ML products and increased productivity from data science teams, giving businesses a competitive edge in this rapidly evolving field.