Deploying Large Language Models (LLMs) into real-world applications goes beyond simple model training. The process involves multiple phases, such as data preparation, model fine-tuning, deployment, and continuous performance monitoring. These stages demand seamless coordination among diverse teams, from data engineers to machine learning experts, making efficient operations critical. This is where LLMOps comes in.
Much like DevOps did for software development, LLMOps focuses on optimizing the entire lifecycle of LLMs, ensuring smooth transitions from research to production, maintaining model quality, and enabling continuous iteration. With LLMOps, businesses can manage the complexities of LLM integration and keep models performing at their best. In this blog, we will explore the fundamentals of LLMOps, distinguish it from MLOps, and share best practices for leveraging LLMs in commercial applications. We will also discuss its building blocks, real-world examples, future trends, and more. Let’s begin!
LLMOps, short for Large Language Model Operations, is an emerging discipline that sits at the crossroads of MLOps and the unique challenges posed by large language models. Moreover, it encompasses a set of practices, tools, and methodologies designed to streamline the development, deployment, and maintenance of LLMs.
Indeed, Think of LLMOps as the secret sauce that enables organizations to harness the power of LLMs effectively. It’s the behind-the-scenes maestro that orchestrates the entire lifecycle of these models, from data preparation to model training, deployment, and beyond.
At its core, LLMOps is all about managing the intricacies of large language models. Besides, it involves overseeing the entire journey of an LLM, from its inception to its real-world application. This includes tasks such as data curation, model architecture design, training, fine-tuning, testing, deployment, and continuous monitoring.
LLMOps platforms, in addition, can provide what are thought of as typical MLOps functionalities:
Several key components form the backbone of LLMOps. These include:
The primary benefits of LLMOps can be grouped under three major headings: efficiency, risk reduction, and scalability.
As AI continues to evolve, LLMOps has become a crucial component in the AI landscape. It enables organizations to:
Without a robust LLMOps strategy, organizations risk facing challenges such as inconsistent model performance, difficulties in scaling, and increased maintenance overhead. It provides a structured approach to mitigate these risks and unlock the full potential of LLMs.
LLMOps and MLOps share a common goal – to streamline the lifecycle of AI models. However, LLMOps specifically caters to the unique characteristics and requirements of large language models.
MLOps, or Machine Learning Operations, is a well-established practice that aims to bring the principles of DevOps to the world of machine learning. It focuses on automating and streamlining the end-to-end process of developing, deploying, and maintaining ML models.
LLMOps, on the other hand, is a specialized subset of MLOps that focuses specifically on the unique challenges and requirements associated with developing, deploying, and managing large language models.
While both disciplines share the common objective of operationalizing AI models, LLMOps dives deeper into the intricacies of LLMs.
Large language models present a unique set of challenges that necessitate a specialized approach. Some of these challenges include:
LLMOps involves managing the entire lifecycle of LLMs, from data preparation and model training to deployment and monitoring. In addition, this requires specialized tools and infrastructure to handle the massive computational resources needed for training and deploying LLMs.
While LLMOps share many similarities with traditional MLOps practices, it also presents unique challenges due to the scale and complexity of large language models. Adapting MLOps practices for LLMOps requires considering the specific requirements of LLMs, such as:
By tailoring MLOps practices to the specific needs of LLMs, organizations can effectively address the challenges posed by these models and unlock their full potential.
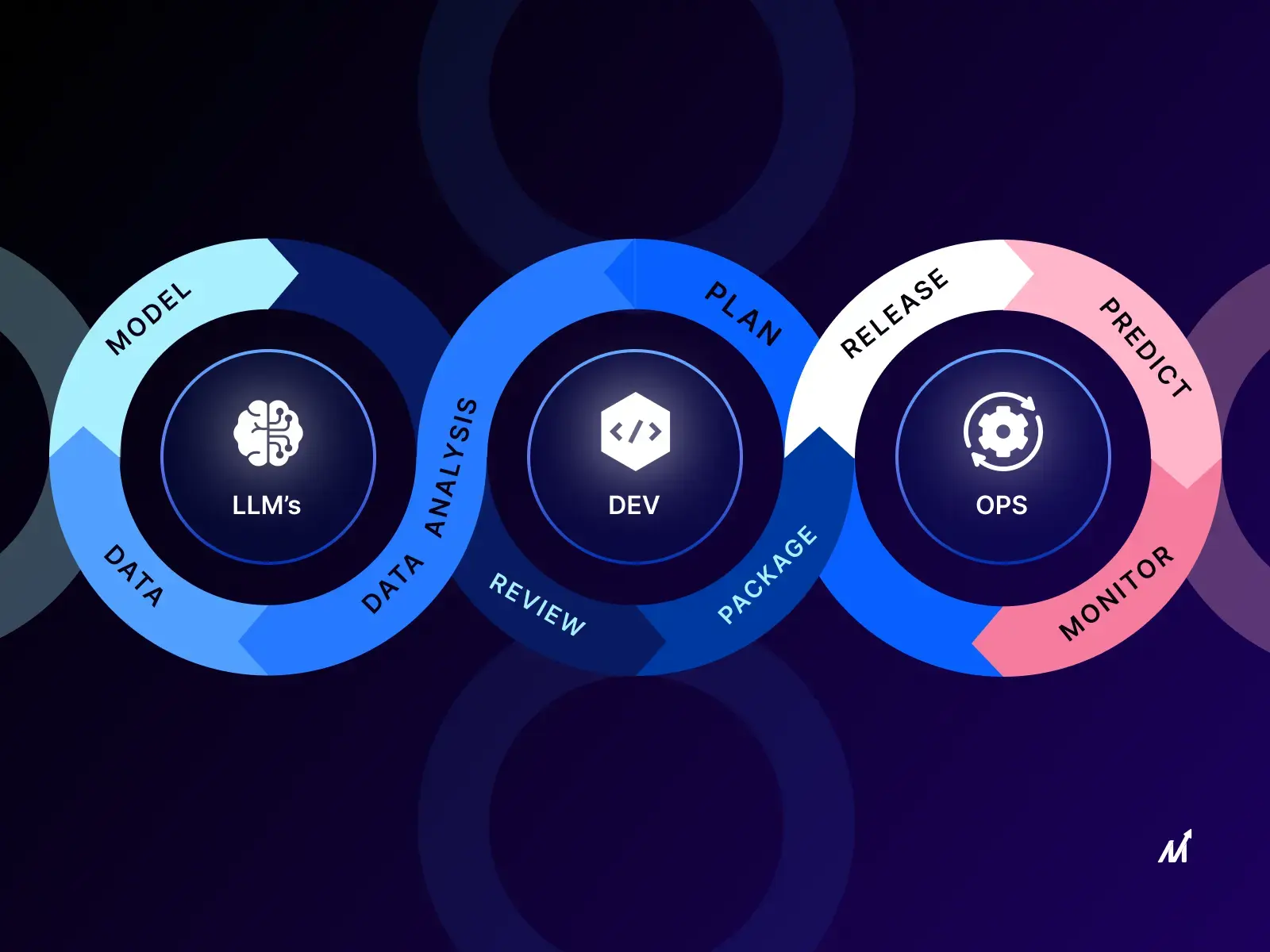
LLMOps is a multifaceted discipline that encompasses various elements, each playing a crucial role in the successful operationalization of large language models. Furthermore, let’s take a closer look at the core foundation blocks of LLMOps.
LLMOps require specialized infrastructure and computational resources to handle the massive scale of large language models. This includes:
Building and maintaining this infrastructure requires a deep understanding of the unique requirements of LLMs and the ability to optimize resource utilization for cost-effectiveness and performance.
LLMOps involves using specialized tools for data management, model training, deployment, and monitoring. Additionally, some essential tools in the LLMOps toolkit include:
These tools form the backbone of the LLMOps workflow, enabling teams to efficiently manage and automate various stages of the LLM lifecycle.
LLMOps encompasses several key processes that are critical for the successful development and deployment of large language models. These processes include:
By establishing well-defined processes and best practices around these key areas, organizations can ensure the smooth and efficient operation of their LLM workflows.
LLMOps plays a crucial role in every stage of the LLM lifecycle, from data preparation to model deployment and maintenance. Additionally, let’s explore how LLMOps support and streamline each phase of the LLM journey.
Data is the fuel that powers LLMs, and effective data management is essential for building high-performing models. LLMOps practices help organizations:
Once the foundation model is chosen, it is time to collect, curate, and preprocess the data that will be used to train the model. The data must be unbiased and representative of the desired content.
Training LLMs is a computationally intensive process that requires specialized infrastructure and tools. LLMOps streamline the training process by:
The next stage is LLMOps training, an iterative process used to create and improve the LLM. Furthermore, multiple rounds of training, evaluation, and adjustments are required to reach and sustain high levels of accuracy and efficiency. A variety of approaches can be used to adapt the LLM, and they include:
Ensuring the quality and reliability of LLMs is critical before deploying them to production. LLMOps supports rigorous evaluation and testing practices, including:
Model evaluation and testing are critical components of the LLM lifecycle. LLMOps involves rigorous testing and evaluation of LLMs to ensure their performance, accuracy, and reliability before deployment.
Deploying LLMs to production environments requires careful planning and execution. LLMOps practices help organizations:
When it comes time to deploy the LLM, LLMOps can do so through on-premise, cloud-based, or hybrid solutions. The choice between deployment methods largely hinges on infrastructure considerations such as hardware, software, and networks, as well as the organization’s specific needs. At this stage, security and access controls are paramount to protect the LLM and its data from misuse, unauthorized access, and other security threats.
Ensuring the long-term performance and reliability of LLMs requires ongoing monitoring and maintenance. LLMOps supports these activities by:
LLMOps is not just about managing the technical aspects of large language models; it’s also about driving tangible improvements in model performance and operational efficiency. By adopting LLMOps practices, organizations can unlock the full potential of their LLMs and achieve better results with less effort.
One of the primary goals of LLMOps is to optimize the performance of LLMs in terms of accuracy, speed, and resource utilization. This involves:
LLMOps enable easier scalability and management of data, which is crucial when thousands of models need to be overseen, controlled, managed, and monitored for continuous integration, continuous delivery, and continuous deployment. LLMOps can do this by improving model latency, which can be optimized to provide a more responsive user experience.
Key Takeaway
LLMOps, blending MLOps with the unique needs of large language models, lets teams smoothly run AI projects. Moreover, it’s all about managing data to deployment and everything in between. By focusing on efficiency, reducing risks, and scaling up smartly, LLMOps is key for nailing AI goals.
After working with various companies, we’ve learned that making LLMOps run smoothly comes down to a few things: setting up a clear plan, getting your data in order, and keeping tabs on your models properly.
The first step in implementing LLMOps is to establish a comprehensive framework that covers the entire LLM lifecycle. Hence, this framework should define the processes, tools, and best practices for developing, deploying, and managing LLMs in your production environments. Additionally, it’s crucial to involve all stakeholders, including data scientists, ML engineers, and DevOps teams, in the framework creation process to ensure everyone is aligned and working towards the same goals.
Data preparation is a critical aspect of LLMOps. First step? We pull together all the data, sort it out neatly, and prep it for a deep dive into training large language models. In my experience, using feature stores can significantly streamline this process. Feature stores manage and store preprocessed data features, enabling efficient data management and reuse across multiple LLM projects. This not only saves time but also ensures consistency in data used for training and inference.
As you develop and refine your LLMs, it’s essential to keep track of different model versions and their dependencies. Model versioning and management tools help you track the lineage of your models, ensuring reproducibility and traceability. This is particularly important when you need to roll back to a previous version or investigate issues in production.
Once your LLMs are deployed, it’s crucial to monitor their performance and behavior continuously. Implementing comprehensive monitoring and logging systems allows you to track model performance metrics, detect anomalies, and troubleshoot issues in real-time. I recommend setting up alerts and dashboards to provide visibility into the health and performance of your LLMs.
To truly appreciate the power of LLMOps, let’s take a look at some real-world examples of how organizations have successfully implemented LLMOps and the impact it has had on their business outcomes.
One of the most impressive examples of LLMOps implementation I have come across is in the financial services industry. A leading bank leveraged LLMOps to develop an AI-powered chatbot for customer service. Through utilizing LLMOps best practices, they were able to train the model on a vast amount of customer interaction data, continuously monitor and improve its performance, and seamlessly integrate it into their existing systems. Consequently, the result was a significant reduction in customer wait times and a 30% increase in customer satisfaction scores.
Another inspiring example comes from the healthcare sector.
A renowned hospital implemented LLMOps to develop an AI system for analyzing medical records and assisting doctors in making accurate diagnoses. By establishing a robust LLMOps framework, they ensured the model was trained on high-quality, unbiased data and underwent rigorous testing and validation before deployment. The AI system has proven to be a game-changer, helping doctors make faster and more accurate diagnoses and ultimately improving patient outcomes.
It’s pretty clear, when you look at the numbers, just how much of a game-changer LLMOps is for any business outcome. Companies diving into LLMOps have seen their work get smoother, costs go down, and customers walk away happier. For instance, a leading e-commerce company that adopted LLMOps for their product recommendation system saw a 25% increase in click-through rates and a 15% boost in sales.
Another company in the manufacturing sector used LLMOps to optimize their supply chain operations. By leveraging LLMs to analyze vast amounts of data from sensors, logistics systems, and customer feedback, they were able to predict demand more accurately, reduce inventory costs, and improve delivery times. Consequently, the result was a staggering 20% reduction in operational costs and a 95% on-time delivery rate.
Implementing LLMOps is not without its challenges, but the lessons learned from real-world implementations are invaluable. One of the key takeaways is the importance of starting small and iterating quickly. Besides, many successful organizations began with a pilot project, learned from their mistakes, and gradually scaled up their LLMOps efforts.
Another crucial lesson is the significance of data quality. Ensuring that your LLMs are trained on high-quality, diverse, and unbiased data is essential for achieving accurate and reliable results. Investing time and resources in data preparation and curation pays off in the long run. Finally, successful LLMOps implementation requires a culture of collaboration and continuous improvement.
As we dive deeper into the world of LLMOps, it’s crucial to address the ethical considerations and challenges that come with developing and deploying large language models.
One of the most significant ethical challenges in LLMOps is ensuring that the models are unbiased and fair. LLMs are only as unbiased as the data they are trained on. Thus, if that data contains historical biases or underrepresents certain groups, the model’s outputs can perpetuate those biases. Consequently, it’s essential to actively identify and mitigate biases in the training data and regularly audit the model’s outputs for fairness.
Techniques like adversarial debiasing, where the model is trained to be invariant to protected attributes like race or gender, can help reduce bias. Additionally, ensuring diverse representation in the teams developing and deploying LLMs can bring different perspectives and help catch potential biases early on.
Another key ethical consideration in LLMOps is transparency and explainability. As LLMs become more complex and are used in high-stakes decision-making processes, it’s crucial to understand how they arrive at their outputs. Black-box models that provide no insight into their reasoning can be problematic, especially in industries like healthcare or criminal justice, where decisions can have significant consequences.
Additionally, techniques like attention visualization and interpretable machine learning can help shed light on how LLMs process information and generate outputs. Clear explanations of model workings and involving domain experts in development enhance transparency and build stakeholder trust.
LLMs, like any powerful technology, come with risks of misuse and unintended consequences. In addition, one concerning example is the potential for LLMs to be used to generate fake news, propaganda, or hate speech at scale. There’s also the risk of prompt injection attacks, where malicious actors craft inputs that manipulate the model’s outputs for harmful purposes.
Besides, to keep things safe, we really need to put some strong checks in place and watch closely for any signs of trouble. This can include content filters, user authentication, and regular audits of the model’s outputs. Providing clear guidelines on the appropriate use of LLMs and educating stakeholders on potential risks can also help prevent unintended consequences.
Moreover, addressing these ethical challenges requires ongoing collaboration between LLMOps practitioners, ethicists, policymakers, and the broader community. Consequently, by proactively considering and addressing these issues, we can ensure that principles of fairness, transparency, and social responsibility guide the development and deployment of LLMs.
Peeking into the future, it’s easy to see that LLMOps is on a fast track to becoming bigger and even more inventive. The rapid advancements in large language models and the increasing adoption of AI across industries present both exciting opportunities and challenges for businesses and researchers alike.
One of the key trends shaping the future of LLMOps is the increasing availability and accessibility of open-source models and tools. Likewise, platforms like Hugging Face and initiatives like EleutherAI are democratizing access to state-of-the-art language models, enabling more organizations to leverage the power of LLMs without the need for extensive resources or expertise.
Furthermore, another trend to watch is the growing interest in domain-specific LLMs. While general-purpose models like GPT-3 have shown impressive capabilities across a wide range of tasks, there’s a growing recognition of the value of specialized models tailored to specific industries or use cases. Get ready for a leap forward as sharper tools come online to transform how we handle health care plans, financial advice, and legal matters. Indeed, it’s going to be quite the game-changer.
The field of LLMOps is being propelled forward by a wave of exciting innovations. Particularly, one of the most promising areas is retrieval augmented generation (RAG), which combines the strengths of LLMs with external knowledge bases to generate more accurate and informative outputs. By leveraging techniques like vector databases and semantic search, RAG enables LLMs to access and incorporate relevant information from vast repositories of knowledge. Thus, this opens up new possibilities for question-answering, content generation, and decision support.
Another innovation gaining traction is LLM chaining, where multiple language models are combined in a pipeline to tackle complex, multi-step tasks. By breaking down a problem into smaller sub-tasks and assigning each to a specialized model. Additionally, LLM chaining can enable more efficient and effective problem-solving. This approach is particularly promising for applications like dialogue systems, where multiple skills like language understanding, knowledge retrieval, and response generation need to work together seamlessly.
As LLMOps quickly advances, it’s offering businesses golden chances to make the most out of language AI technologies. Furthermore, the applications range across a wide range of domains, from customer service and content creation to research and development.
For researchers, the future of LLMOps is equally exciting. The field is ripe for exploration and innovation, offering countless opportunities to push language model boundaries. Moreover, researchers play a crucial role in shaping the future, refining training techniques, and exploring new paradigms.
As we journey into LLMOps’ future, collaboration, curiosity, and responsibility are essential. Moreover, by advancing the field with ethics, transparency, and social impact, we unlock language AI’s full potential for societal benefit.
The future of LLMOps is bright, and I, for one, can’t wait to see where it takes us.
Key Takeaway
LLMOps are key to AI success, focusing on a clear framework, efficient data prep, solid model management, constant monitoring, and strong teamwork. Similarly, real-world examples show its huge impact across industries.
In the swiftly evolving AI domain, businesses seek methods to streamline operations and boost innovation. Markovate leads with Lifecycle Machine Learning Operations (LLMOps). Additionally, this cutting-edge approach meticulously integrates machine learning models into corporate ecosystems, thereby enhancing efficiency and fostering innovation.
Markovate’s proficiency in LLMOps is designed to address and simplify complexities associated with deploying, maintaining, and scaling Large Language Models (LLMs). By customizing AI solutions that resonate with an enterprise’s unique objectives, we ensure that AI initiatives transition smoothly from conception to execution — maximizing impact while minimizing time-to-market.
The journey begins with a thorough evaluation of an organization’s existing frameworks and data-handling mechanisms. Consequently, identifying areas ripe for improvement or overhaul is critical in laying down robust pipelines. These pipelines automate essential processes such as data preparation, model training/testing, and deployment phases—thus ensuring seamless lifecycle management of machine learning projects.
Additionally, post-deployment stages require vigilant monitoring to assess performance against predefined metrics continuously. In this regard, Markovate stands out, offering advanced tools that promptly detect deviations or anomalies. Besides, these tools enable swift corrective measures, ensuring sustained operational excellence over time.
Markovate’s distinction lies in democratizing sophisticated technologies in boardrooms. Likewise, empowering teams with tailored LLMOps workshops ensures sustainable success beyond the initial implementation phases.
Moreover, embracing LLMOps with Markovate means navigating digital landscapes adeptly. Improved agility drives innovation efficiencies within enterprises, positioning them for future challenges and opportunities.
LLMOps streamline AI workflows, making large language models smarter and faster. It’s all about efficiency.
MLOps focuses on machine learning systems; LLMOps zeroes in on managing hefty language models specifically.
The journey starts with data prep, sails through training and fine-tuning, then lands at deployment and upkeep.
In essence, it’s keeping big talkers—large language models—in check so they perform well when deployed live.
Quote turnaround time gets blamed on pricing. In most shops, that's not where the delay…
A shop wins an RFQ for a part that starts as a permanent mold casting.…
A PDF drawing and a CAD file arrive in the same package. Both represent the…
A CAD-PLM Manager at a global ceramics manufacturing company recently described their quoting challenge in…
A precision injection molding operation with global reach recently described its quoting challenge plainly. They…
Blueprint takeoff has always been the foundation of project estimation. Whether you are bidding on…



