Modern enterprises no longer build AI on standalone machine learning pipelines. Today’s production AI systems rely on a layered AI tech stack that combines large language models (LLMs), vector databases, RAG pipelines, agent orchestration frameworks, and cloud infrastructure — all working together to deliver reliable, scalable AI at the enterprise level.
So, what is an AI tech stack? In an enterprise context, an AI tech stack is a layered architecture that supports the full AI lifecycle — from data ingestion and model selection to deployment, observability, and governance. It goes far beyond individual tools or models; it is the engineering foundation that determines whether an AI system can operate reliably in production.
This blog covers the core layers of a modern AI stack, the essential components enterprises need in 2026, and how to evaluate and select the right technologies to build production-ready AI systems at scale.
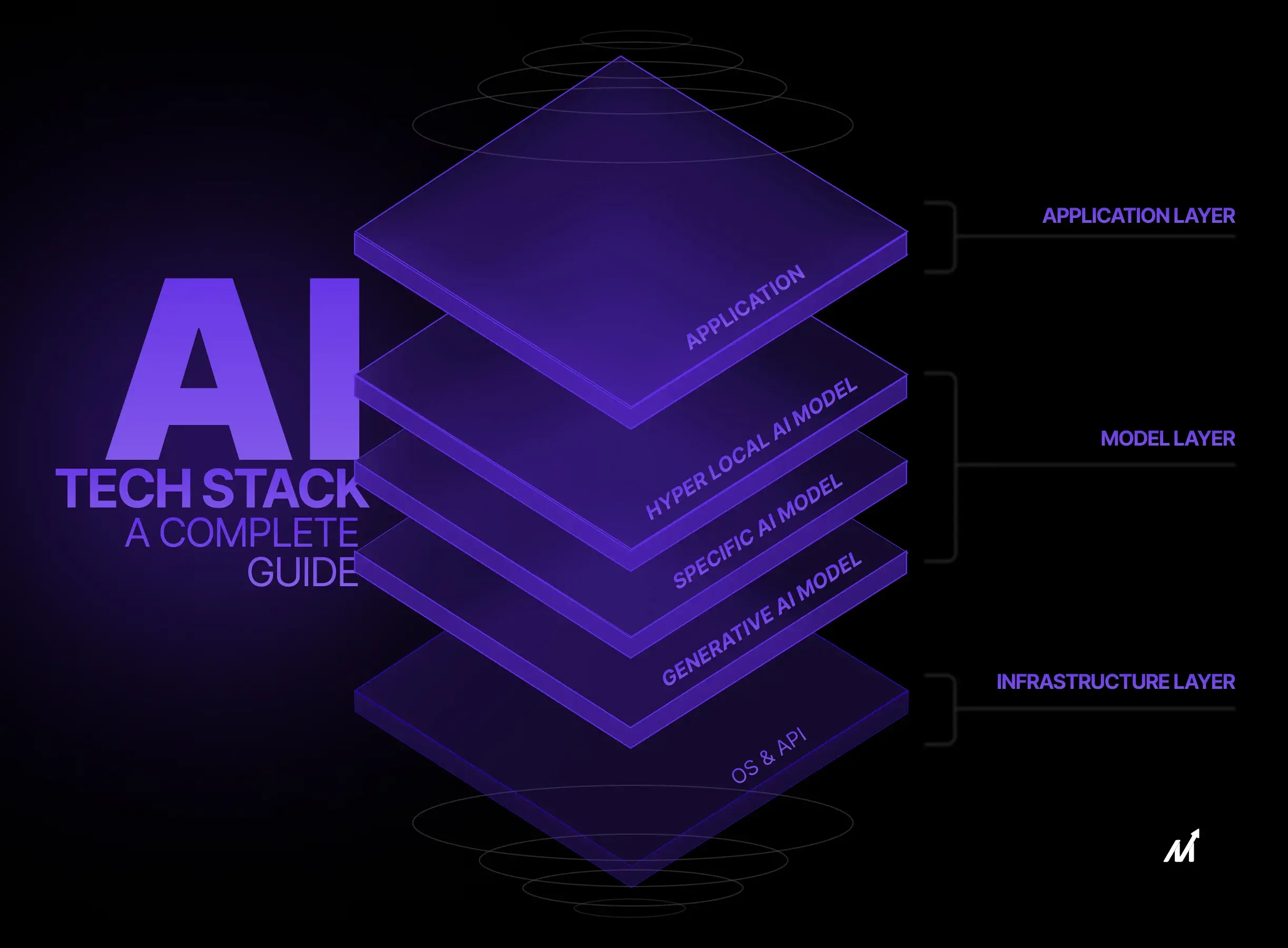
The AI stack is a structural framework comprising interdependent layers, each serving a critical function to ensure the system’s efficiency and effectiveness. Unlike a monolithic architecture, where each component is tightly coupled and entangled, the AI stack’s layered approach allows for modularity, scalability, and easy troubleshooting.
This architecture comprises critical components such as data ingestion, data management, real time data processing, machine learning algorithms, APIs, and user interfaces. These layers act as the foundational pillars that support the intricate web of algorithms, data pipelines, and application interfaces in a typical AI system. Let’s understand these layers in depth.
The Application Layer is the manifestation of user experience, encapsulating elements from web applications to REST APIs that manage data flow between client-side and server-side environments. Additionally, this layer handles essential operations. It captures inputs via GUIs, renders visualizations on dashboards, and provides data-driven insights through API endpoints.
Technologies like React for frontend and Django for backend are often employed, each chosen for their specific advantages in tasks such as data validation, user authentication, and API request routing. The Application Layer serves as a gateway that routes user requests to underlying machine learning models, including those powering computer vision and Natural Language Processing features, while also maintaining stringent security protocols to protect data integrity.
Transitioning to the Model Layer, this is the engine room of decision-making and data processing. Specialized libraries such as TensorFlow or PyTorch take the helm here, offering a versatile toolkit for a range of machine learning activities including but not limited to natural language understanding, computer vision, and predictive analytics. Feature engineering, model training, hyperparameter tuning, and model deployment preparation for AI models occur in this domain.
Different ML algorithms—from regression models to complex neural networks—are scrutinized for performance metrics such as precision, recall, and F1-score. This layer acts as an intermediary, pulling in data from the Application Layer, performing computation-intensive tasks, and then pushing the insights back to be displayed or acted upon.
The Infrastructure Layer is fundamental for training, deploying, and running inference on machine learning models. This layer is where computational resources such as CPUs, GPUs, and TPUs are allocated and managed. Scalability, latency, and fault tolerance are engineered at this level using orchestration tools like Kubernetes for container management.
On the cloud side, services like AWS’s EC2 instances or Azure’s AI-specific accelerators can be incorporated to provide the heavy lifting in terms of computation. This infrastructure is not merely a passive recipient of requests but a dynamic entity programmed to allocate resources judiciously.
Load balancing, data storage solutions, and network latency are all engineered to meet the specific needs of the above layers, ensuring that bottlenecks in computational power do not become a stumbling block for the application’s performance.
Book a 30-minute consultation with our AI experts to get personalized guidance on selecting the best tools and frameworks for your project. We’ll help you avoid costly mistakes and ensure your AI solution is set up for success.
The architecture encompassing artificial intelligence (AI) solutions entails multifaceted modules, each specialized in discrete tasks but cohesively integrated for comprehensive functionality. The sophistication of this stack of technologies is instrumental in driving AI’s capabilities from data ingestion to final application. Below are the various components that make up the AI tech stack:
Before any AI processing occurs, the foundational step is the secure and efficient storage of data. Storage solutions such as SQL databases for structured data and NoSQL databases for unstructured data are essential.
For large-scale data, Big Data solutions like Hadoop’s HDFS and Spark’s in-memory processing become necessary. The type of storage selected directly impacts the data retrieval speed, which is crucial for real-time analytics and machine learning pipelines.
In modern generative AI stacks, vector databases have become an essential storage layer alongside traditional SQL and NoSQL systems. Tools like Pinecone, Weaviate, and pgvector enable high-speed similarity search over embedded representations of text, images, and documents — making them foundational to Retrieval-Augmented Generation (RAG) pipelines, semantic search, and AI agent memory.
Following storage, raw data undergoes the meticulous task of preprocessing and feature identification. Preprocessing transforms raw data through normalization, handling missing values, and outlier detection. These steps are performed using libraries such as Scikit-learn and Pandas in Python.
Feature identification is pivotal for dimensionality reduction and is executed using techniques like Principal Component Analysis (PCA) or Feature Importance Ranking. These cleansed and reduced features become the input for machine learning algorithms, ensuring higher accuracy and efficiency.
Once the preprocessed data is available, machine learning algorithms are employed. Algorithms like Support Vector Machines (SVMs) for classification, Random Forest for ensemble learning, and k-means for clustering serve specific roles in data modeling.
The choice of algorithm directly impacts computational efficiency and predictive accuracy and therefore must be in line with the problem’s requirements.
As computational problems grow in complexity, traditional machine-learning algorithms may fall short. This necessitates the use of deep learning frameworks such as TensorFlow, PyTorch, or Keras to build advanced AI models and neural network architectures.
These frameworks support the construction and training of complex neural network architectures like Convolutional Neural Networks (CNNs) for image recognition or Recurrent Neural Networks (RNNs) for sequential data analysis.
When it comes to interpreting human language, Natural Language Processing (NLP) libraries like NLTK and spaCy serve as the foundational layer. For more advanced applications like sentiment analysis, question answering, and document understanding, large language models (LLMs) — including GPT-4o, Claude, Gemini, and open-source options like Llama 3 and Mistral — offer far greater understanding and contextual reasoning than earlier transformer models like BERT.
These NLP tools and models are usually integrated into the AI stack following deep learning components for applications requiring natural language interaction.
In the realm of visual data, computer vision technologies such as OpenCV are indispensable. Advanced applications may leverage CNNs for facial recognition, object detection, and more. These computer vision components often work in tandem with machine learning algorithms to enable multi-modal data interpretation.
For physical applications like robotics and autonomous systems, sensor fusion techniques are integrated into the stack. In addition, algorithms for Simultaneous Localization and Mapping (SLAM) and decision-making algorithms like Monte Carlo Tree Search (MCTS) are implemented. These elements function alongside the machine learning and computer vision components, driving the AI’s capability to interact with its environment.
The entire AI tech stack often operates within a cloud-based infrastructure like AWS, Google Cloud, or Azure. Therefore, these platforms provide scalable, on-demand computational resources that are vital for data storage, processing speed, and algorithmic execution. The cloud infrastructure acts as the enabling layer that allows for the seamless and integrated operation of all the above components.
The rise of generative AI and autonomous agents has introduced a new set of components that sit on top of traditional ML infrastructure. Enterprises building production AI systems in 2026 must account for all of the following layers.
The model layer today is dominated by large language models (LLMs) from providers including OpenAI (GPT-4o), Anthropic (Claude), Google (Gemini), and Meta (Llama 3). Enterprises choose between API-based access to proprietary models and self-hosted open-source models depending on cost, data privacy requirements, and latency constraints.
Enterprises evaluating which model approach suits their needs can explore AI consulting services to assess the right fit.
Vector databases store and retrieve high-dimensional embeddings generated by language models. They are the backbone of semantic search and RAG pipelines. Leading options include Pinecone, Weaviate, Chroma, and pgvector (for teams preferring PostgreSQL-native solutions).
RAG is the dominant pattern for grounding LLM responses in enterprise data. A RAG pipeline retrieves relevant documents from a vector database at query time and passes them to the LLM as context — significantly reducing hallucinations and enabling the model to answer questions based on private, up-to-date information.
AI agents extend LLMs with the ability to use tools, call APIs, retain memory, and execute multi-step workflows autonomously. More advanced production systems now use multi-agent architectures — where specialised agents handle distinct tasks and coordinate outputs across a shared pipeline. Frameworks like LangChain, LangGraph, LlamaIndex, and CrewAI are widely used to build and coordinate these systems. This is what enables AI to complete complex, real-world tasks end-to-end rather than responding to single prompts.
A practical example of this in production: CADIAM™ by Markovate is a technology powering a catalog of drawing-intelligence agents — each specialised for a specific engineering task (BOM extraction, P&ID reading, takeoff, compare, GD&T) — independently callable via API or composable into a full end-to-end workflow. It illustrates how multi-agent architectures move from concept to production in an enterprise context.
Production AI systems require continuous monitoring for accuracy drift, hallucination rates, latency, and cost. Observability platforms like LangSmith, Arize AI, and WhyLabs provide the visibility teams need to maintain model reliability in production.
Serving LLMs efficiently at scale requires specialized inference tooling. Frameworks like vLLM and Ollama are commonly used for high-throughput, low-latency inference — particularly for teams running self-hosted open-source models.
As enterprise AI has evolved, so has the underlying stack. The table below shows how key layers have shifted from traditional ML-based systems to modern generative AI architectures.
| Layer | Traditional AI Stack | Modern GenAI Stack |
| Models | Custom-trained TensorFlow / PyTorch models | Pre-trained LLMs (GPT-4o, Claude, Llama 3) |
| Storage | SQL / NoSQL databases | SQL + Vector databases (Pinecone, Weaviate) |
| Retrieval | Keyword search | RAG pipelines with semantic search |
| Orchestration | REST APIs and batch scripts | AI agent frameworks (LangGraph, LlamaIndex) |
| Deployment | Batch inference | Real-time inference (vLLM, cloud endpoints) |
| Observability | Application logs | LLM-specific monitoring (LangSmith, Arize) |
A well-architected AI tech stack fundamentally comprises multifaceted application frameworks that offer an optimized programming paradigm, readily adaptable to emerging technological evolutions.
For instance, frameworks like LangChain, Fixie, Microsoft’s Semantic Kernel, and Vertex AI by Google Cloud equip engineers to build applications equipped for autonomous content creation, semantic comprehension for natural language search queries, and task execution through intelligent agents.
Situated at the heart of the AI tech stack are the Foundation Models (FMs), essentially serving as the cognitive layer that enables complex decision-making and logical reasoning. Whether it’s in-house creations from enterprises like OpenAI, Anthropic, or Cohere or open-source alternatives, these models offer a vast spectrum of capabilities.
Engineers can leverage multiple FMs to enhance application performance. Model Deployment options include both centralized server architectures and edge computing, offering benefits such as reduced latency and improved security.
Language Learning Models (LLMs) possess the capability to make inferences based on their training data. To maximize efficacy and precision, engineers must establish robust data operationalization protocols.
Data loaders, vector databases, and similar tools become instrumental in ingesting both structured and unstructured datasets, facilitating efficient storage and query execution. Moreover, technologies like retrieval-augmented generation add another layer of customization to the model outputs.
Navigating the trade-offs among model efficiency, fiscal expenditure, and response latency is a significant hurdle in the realm of generative AI. Engineers employ an array of diagnostic utilities to fine-tune this balance, including prompt optimization, real-time performance analytics, and experimental tracking.
For these purposes, a myriad of No Code/Low Code tools, tracking utilities, and specialized platforms such as WhyLabs’ LangKit are at the developers’ disposal.
The ultimate goal in the developmental pipeline is to transition applications from experimental stages to live production environments. Engineers have the flexibility to opt for self-hosting or enlist third-party deployment services. Moreover, various facilitators like Fixie streamline the construction, dissemination, and implementation phases of AI application deployment.
In summary, the AI tech stack is an all-encompassing infrastructure, supporting the life cycle of intelligent application creation from conceptualization to live production. This intricate system provides the technical scaffolding that revolutionizes how applications are built, how information is synthesized, and how tasks are executed.
It embodies a transformative methodology that redefines both the technological landscape and the operational modalities of contemporary work environments. If you want to learn how you can leverage the AI tech stack for your business solutions, refer to AI consulting services.
The necessity of a meticulously curated technology stack in constructing robust AI systems cannot be overstated. Therefore, from machine learning frameworks to programming languages, cloud services, and data manipulation utilities, each element plays a pivotal role. Below is a technical breakdown of these critical constituents.
The architecture of AI models necessitates advanced machine learning frameworks for training and inference. TensorFlow, PyTorch, and Keras are not mere libraries; they’re ecosystems that offer an arsenal of tools and Application Programming Interfaces (APIs) to build, optimize, and validate machine learning models.
They also host a spectrum of pre-configured models for tasks ranging from natural language processing to computer vision. Such frameworks must form the bedrock of the technology stack, offering avenues to adapt models for specific metrics like precision, recall, or F1 score.
The choice of programming language is consequential to the harmonious interplay between user accessibility and model efficiency. Python stands as the lingua franca of machine learning, owing to its readability and exhaustive package repositories.
While Python predominates, languages such as R and Julia also find applications, particularly for statistical analysis and high-performance computing tasks, respectively.
The computational and storage demands of generative AI models are far from trivial. The integration of cloud services in the technology stack furnishes these models with the requisite horsepower.
Services such as Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure render configurable resources like virtual machines, along with dedicated machine learning platforms. The cloud infrastructure’s innate scalability ensures that the AI systems can adapt to varying workloads without sacrificing performance or incurring downtime.
Organizations looking to build on this infrastructure can also explore enterprise AI development services tailored to their cloud environment.
Raw data is seldom ready for immediate model training; preprocessing steps like normalization, encoding, and imputation are often imperative. In addition, utilities like Apache Spark and Apache Hadoop offer data processing capabilities that can manage voluminous datasets with efficiency. Additionally, their added functionality for data visualization aids in exploratory data analysis, facilitating the uncovering of hidden trends or anomalies within the data.
By methodically selecting and integrating these components into a cohesive technology stack, one achieves not just a functional AI system but an optimized one. The system thus assembled will exhibit enhanced accuracy, greater scalability, and reliability, which are indispensable for the rapid evolution and deployment of AI applications.
It is the blend of these well-chosen resources that makes a technology stack not just comprehensive but also instrumental in achieving the highest echelons of performance in AI systems.
Read more about how to build an AI system
To effectively build, deploy, and scale AI solutions, a systematic framework is indispensable. Consequently, serving as the backbone for AI applications, offering a layered approach to tackling the multifaceted challenges posed by AI development. This framework is usually divided into distinct phases, each responsible for a particular aspect of the AI life cycle, such as data management, data transformation, and machine learning, among others. Let’s understand each of these phases to understand each layer’s importance, tools, and methodologies.
Data is the lifeblood that fuels machine learning algorithms and decision making, coming in the form of structured and unstructured data from diverse enterprise and user-generated sources. Thus, the first phase of our AI Stack discussion centers around Data Management Infrastructure, a segment vital for obtaining, refining, and making data actionable.
This phase can be subdivided into several stages, each focusing on a specific aspect of data handling, including Data Acquisition, Data Transformation and Storage, and Data Processing Frameworks. Subsequently, we dissect each stage to provide a comprehensive understanding of its mechanisms, tools, and significance.
The data acquisition mechanism is a complex interplay involving an amalgamation of internal toolsets and external applications. These disparate sources coalesce to curate an actionable data set for further operations.
The data harvested is subjected to a labeling process, which is essential for machine-based learning in a supervised environment. Consequently, automation has incrementally taken over this laborious task through software solutions like V7 Labs and ImgLab. Nevertheless, manual scrutiny remains indispensable due to algorithmic limitations in identifying outlier cases.
Notwithstanding the vast volumes of available data, gaps exist, particularly in niche use cases. Therefore, tools like TensorFlow and OpenCV have been employed to create synthetic image data. Libraries like SymPy and Pydbgen are deployed in symbolic expressions and categorical data. Additional utilities like Hazy and Datomize provide integration with other platforms.
ETL and ELT serve as two contrasting paradigms for data transformation. ETL prioritizes data refinement, temporarily staging the data for processing before final storage. In contrast, ELT focuses on practicality, depositing data first and transforming it. Reverse ETL has emerged to sync data stores with end-user interfaces like CRMs and ERPs, democratizing data across applications.
Various methodologies exist for data storage, each fulfilling a specific need. Data lakes excel at storing unstructured data, whereas data warehouses are tailored for storing highly processed, structured data. An array of cloud-based solutions like Google Cloud Platform and Azure Cloud furnish robust storage capabilities.
The data, post-acquisition, must be processed into a digestible form. Libraries like NumPy and pandas are widely utilized for this data analysis phase. In addition, for high-velocity data handling, Apache Spark serves as a potent tool.
Feature stores like Iguazio, Tecton, and Feast are the cornerstones of efficient feature management, significantly enhancing the reliability of feature pipelines across machine-learning applications.
Versioning remains a cornerstone in data management, facilitating reproducibility in an ever-changing data environment. Additionally, tools like DVC are technology-agnostic, integrating seamlessly with various storage mediums. On the lineage front, platforms like Pachyderm offer data versioning and provide an intricate mapping of data lineage, presenting a coherent data narrative.
Automated monitoring solutions like Censius are instrumental in maintaining data quality and identifying discrepancies such as missing values, type conflicts, or statistical variations. Supplementary monitoring tools like Fiddler and Grafana serve similar purposes but add a layer of Complexity by tracking data traffic volumes.
Modeling in the landscape of artificial intelligence and machine learning isn’t a linear process but rather a cyclical one involving iterative advancements and evaluations. It begins after the data has been amassed, appropriately stored, scrutinized, and transmuted into functional attributes. Model development is not just about algorithmic choices but should be the lens of computational constraints, operational conditions, and data security governance.
Machine learning comes with extensive libraries like TensorFlow, PyTorch, scikit-learn, and MXNET, each offering unique selling points—computational speed, flexibility, ease of learning curve, or robust community backing. Once a library aligns with project requirements, one can start the routine procedures of model selection, parameter tuning, and iterative experimentation.
The Integrated Development Environment (IDE) scaffolds AI and software development. Through integration of essential components—code editors, compilation mechanisms, debugging tools, and more—streamlines the development workflow. PyCharm stands out for its ease in dependency management and code linkage, ensuring the project remains stable, even when transitioning between different developers or teams.
Visual Studio Code (VS Code) emerges as another reliable IDE, highly versatile across operating systems and offering integrations with external utilities like PyLint and Node.js. Other IDEs like Jupyter and Spyder are predominantly utilized during the prototyping phase. Traditionally, an academic favorite, MATLAB is gradually gaining ground in commercial applications for end-to-end code support.
The machine learning technology stack is inherently experimental, demanding numerous tests across data subsets, feature engineering, and resource allocation to fine-tune the optimum model. Furthermore, the capacity to replicate experiments is crucial for retracing the developmental trajectory and production deployment.
Tools like MLFlow, Neptune, and Weights & Biases facilitate rigorous experiment tracking. At the same time, Layer offers an overarching platform for managing all project metadata. This ensures a collaborative ecosystem that can dynamically adapt to scale, a significant focus for companies that aim for robust, collaborative machine learning ventures.
Performance assessment in machine learning involves intricate comparisons across multiple experimental outcomes and data divisions. Automated tools such as Comet, Evidently AI, and Censius play a vital role here. These utilities automate monitoring, allowing data scientists to focus on core objectives rather than manual performance tracking.
These platforms provide standard and customizable metric evaluations tailored to generic and nuanced use cases. Detailing performance issues about other challenges, such as data quality degradation or model drifts, becomes indispensable for root cause analysis.
Determining the technical specifications and functionalities of a project plays an instrumental role in the choice of an AI technology stack. Moreover, the magnitude and ambition of the project necessitated a corresponding complexity in the stack. This complexity ranges from the programming languages to the frameworks utilized. Concerning generative AI, the following are the core parameters that need evaluation:
The skills and resources available to the development team are pivotal in the choice of an AI stack. Additionally, the decision-making should be strategic, eliminating any steep learning curves that might impede progress. Considerations in this domain include:
A system’s scalability directly impacts its longevity and adaptability. Besides, an optimal stack should account for vertical scalability—enhanced performance across multiple devices—and horizontal scalability—ease of feature augmentation. Important variables to consider include:
A secure data environment is paramount, particularly when handling sensitive or financial information. Essential security criteria to consider include:
We at Markovate are your partners in developing AI models and solutions tailored to your specific needs, and we have a solid basis in AI development. Our team at Markovate knows the full AI ecosystem, from machine learning techniques to data analytics.
We use a cutting-edge AI Technology Stack, which includes data-focused engines, like Apache Spark and Hadoop, when you collaborate with us as a partner. TensorFlow, PyTorch, and other cutting-edge machine learning frameworks work with these to provide insights that inform and drive decision-making.
Integrating cloud services? We cover it, too. To ensure your AI applications grow and function efficiently, we collaborate with the top cloud computing service providers.
So why choose Markovate? We provide more than simply AI services and technology. Our team offers a road plan for the future, whether it’s generative AI, deep learning, or Machine Learning, one in which your company will not only adapt to change but also benefit from it. We aren’t simply meeting the industry standards but setting them. Join forces with us, and let’s create future AI.
See how we’ve helped other businesses build powerful AI tech stacks. Explore our case studies.
An AI tech stack is the layered set of tools, frameworks, and infrastructure that enables organizations to build, deploy, and scale AI systems. A modern enterprise AI stack typically includes a data pipeline layer, a foundation model layer (LLMs), a retrieval and orchestration layer (RAG pipelines and agent frameworks), and a cloud infrastructure layer for deployment and observability.
A traditional ML stack is built around custom-trained models using frameworks like TensorFlow or Scikit-learn, relying on structured data and batch inference. A modern LLM-based stack uses pre-trained foundation models accessed via API or self-hosted deployment, with vector databases for retrieval, RAG pipelines for grounding model responses in private data, and agent frameworks for multi-step task automation. The shift is from building models from scratch to orchestrating and fine-tuning existing models for specific enterprise use cases.
A modern AI tech stack typically includes several core layers. At the model layer, organizations use LLMs such as GPT-4o, Claude, or Llama 3. Vector databases like Pinecone, Weaviate, or pgvector support retrieval and search. Agent orchestration frameworks such as LangChain, LangGraph, and LlamaIndex coordinate workflows. Inference serving platforms like vLLM and Ollama manage model deployment, while tools such as LangSmith and Arize AI provide observability. The specific tools chosen depend on deployment preferences, data privacy requirements, and the latency and cost constraints of the use case.
Vector databases store numerical representations (embeddings) of text, documents, and other data generated by language models. They enable fast similarity search across large datasets. This capability powers RAG pipelines, allowing AI systems to retrieve the most relevant enterprise information before generating a response. Without a vector database, LLMs can only rely on their training data and cannot access or reason over private, up-to-date business information.
RAG (Retrieval-Augmented Generation) grounds LLM responses in real data. It retrieves relevant documents from a vector database at query time and provides them to the model as additional context. For enterprises, RAG reduces hallucinations, enables AI systems to work with internal documents and databases, and keeps responses current without retraining the model. It has become the dominant architecture for enterprise AI applications, including chatbots, document search, and knowledge assistants.
Enterprise AI deployment typically involves containerised model serving using Kubernetes and Docker, inference optimisation frameworks like vLLM for high-throughput LLM serving, CI/CD pipelines adapted for ML workflows (MLOps), and real-time observability tooling to monitor model accuracy, latency, and cost. Cloud providers — AWS, Azure, and Google Cloud — all offer managed AI deployment services that reduce infrastructure overhead. The choice between fully managed cloud services and self-hosted infrastructure depends on data sensitivity, cost at scale, and the team’s operational maturity.
Key practices include adopting a modular architecture so individual layers can be upgraded independently. Organizations should also implement MLOps pipelines for automated testing and deployment while continuously monitoring models for accuracy drift and performance degradation. Strong data governance, access controls, and scalable cloud infrastructure are equally important for supporting variable inference workloads. As the stack grows, centralizing observability across models and agents becomes critical for maintaining production reliability.
A PDF drawing and a CAD file arrive in the same package. Both represent the…
A CAD-PLM Manager at a global ceramics manufacturing company recently described their quoting challenge in…
A precision injection molding operation with global reach recently described its quoting challenge plainly. They…
Blueprint takeoff has always been the foundation of project estimation. Whether you are bidding on…
A large-scale oil and gas refinery operation reached out recently with a clear, specific problem.…
Every manufacturing shop prices work differently. Not because estimators are inconsistent — but because no…





